
NAFNet 이란
NAFNet: Nonlinear Activation Free Network for Image Restoration
이 논문은 ECCV2022에 게재된
Simple Baselines for Image Restoration
논문을 pytorch로 구현한 모델이다
이 모델을 가지고 윈도우 환경에서 학습시킬 수 있도록 세팅하는 과정을 알아보자
NAFNet 설치하기

readme에 적혀있는 installation과 quick start를 따라서 설치해보도록 하자

우선 아나콘다 프롬프트를 켜주자
아나콘다 환경 세팅
conda env list위 명령어로 conda 환경이 지금 어떤게 있는지 한 번 봐주고
conda create -n nafnet python=3.9.5권장되는 버전인 python 3.9.5 버전으로 새로운 환경을 만든다
conda activate nafnet들어가서 필요한 것들을 설치해주자
CUDA 설치
nvidia-smi
nvcc --version
위 명령어로 cuda 드라이버와 toolkit 설치를 확인하자
아무것도 안나온다면?
CUDA toolkit 설치하기, PyTorch GPU 호환 버전 설치하기 (PyTorch 2.0.1+cpu 오류, CUDA 설치 호환, PyTorch CUDA
PyTorch를 GPU에서 돌아가는 CUDA 호환 버전으로 설치하자. pytorch gpu 호환 확인python -c "import torch; print(torch.cuda.is_available())"이미 pytorch를 설치했다면, gpu가 사용가능한지 확인해보자.사용가능한 상태
like-grapejuice.tistory.com
파이토치 GPU 설치
cuda toolkit까지 설치되었다면 CUDA와 호환되는 파이토치를 설치하자
# CUDA 11.3
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch
git clone 하기
이제 직접 설치가 필요한 요소는 설치했으니 clone을 떠주자
git clone https://github.com/megvii-research/NAFNet
cd NAFNet
pip install -r requirements.txt
python setup.py develop --no_cuda_ext위 명령어를 단계씩 밟으며 필요한 package들을 설치하고 세팅한다
NAFNet 시작하기
NAFNet에는 image Denoise, Deblur, Super-Resolution 모델들이 모두 있다
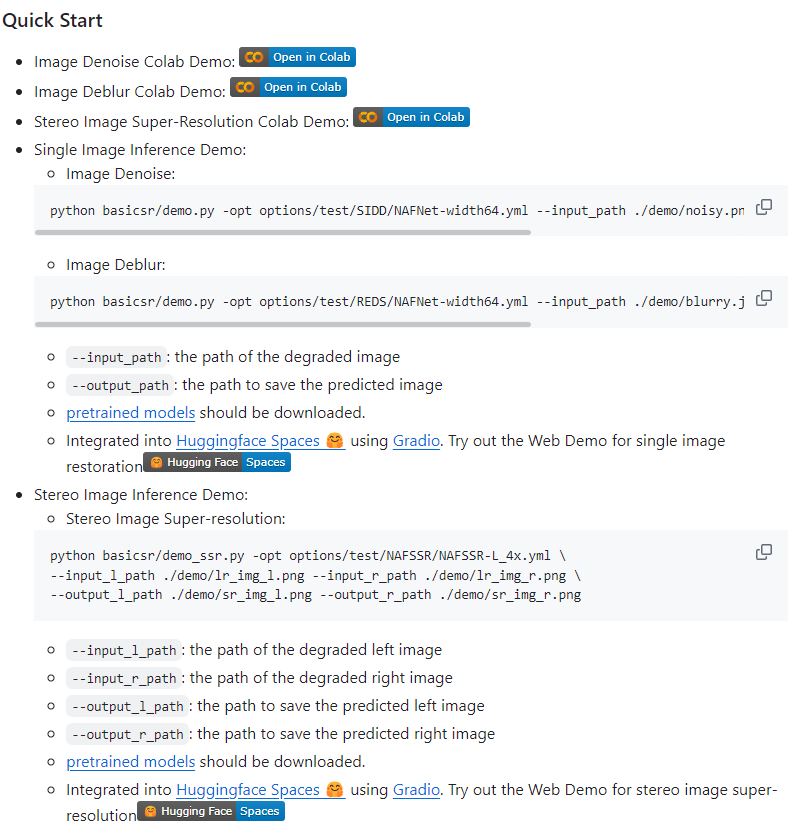
pretrained 된 모델들도 demo를 실행해볼 수 있도록 되어있고
colab이나 hugging face와 같은 사이트에서 브라우저상으로 돌려볼 수도 있다
지금은이 pretrained 모델이 최종 목표가 아니라 직접 training을 돌리는 것이 목표이다
그 방법을 알아보자
dataset
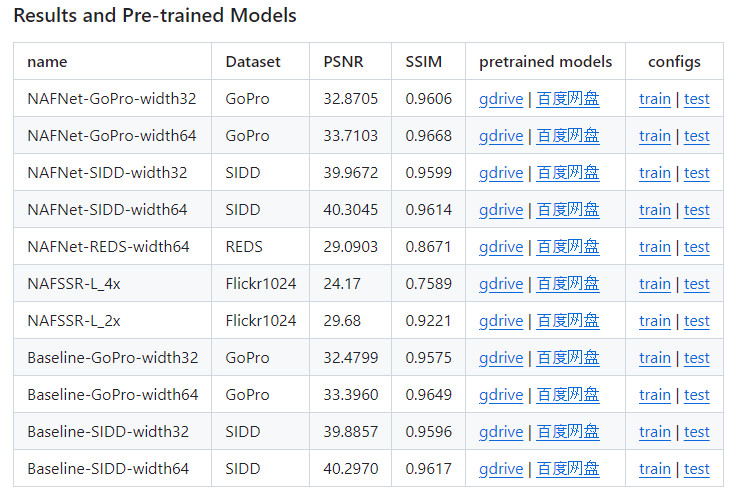
dataset은 GoPro를 사용할 것이다
GoPro dataset을 사용하는 방법을 다음 링크를 참고해보자
어떻게 성능을 향상시킬 것인가 (feat. normalization)
일단 계획은 이렇다
위 코드가 모델의 기본 아키텍처 구조를 나타내는데
여기서 normalization에 해당하는 값을 조정하여서 데이터 범위 제한을 변경해서 학습시켜 볼 것이다
그렇게 시도해서 성능을 향상시키도록 시도해본다
코드에서 \(LayerNorm2d\)라는 변수가 정규화를 담당하고 있다
이 값의 gamma scale와 beta shift등을 조정하는 방법이 있다고 하는데
우선 dataset을 가지고 학습을 돌려보는 방법부터 알아보자
학습 데이터 사전준비 training data set
위에서 결정한 dataset인 GoPro를 가지고 학습 방법을 따라해보며 training을 시도해보자
NAFNet/docs/GoPro.md at main · megvii-research/NAFNet
The state-of-the-art image restoration model without nonlinear activation functions. - megvii-research/NAFNet
github.com
위 GoPro dataset을 가지고 결과를 도출하기 위한 설명서를 읽으며 진행해본다
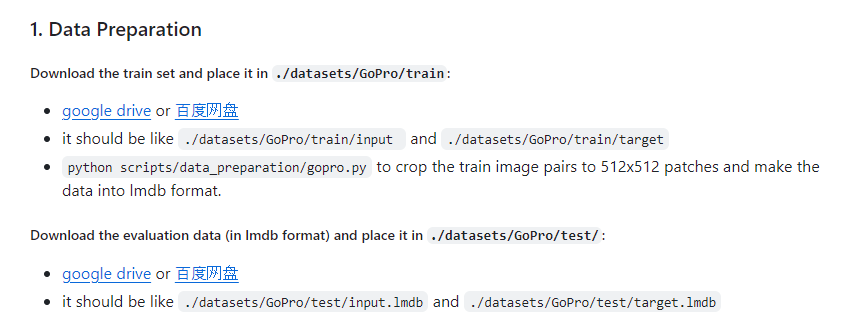
먼저 학습할 dataset을 다운 받자
- train data를 다운받아서 ./datasets/GoPro/train/input 과 ./datasets/GoPro/train/target에 넣는다
- evaluation data를 받아서 ./datasets/GoPro/test/ 에 넣는다
파일 각각 다운 받아주고
(크기가 커서 오래 걸린다... 인터넷이 느린 것도 한 몫)
모두 받았다
언급한 폴더 위치에 옮겨두고
python scripts/data_preparation/gopro.py이 명령어를 실행해서 train set 이미지들을 512x512 patch로 crop 해준다
이 과정이 반드시 필요한지는 확신하지 못한다
crop한 추가 데이터가 있으면 좋고 아니어도 학습을 할 수 있을 것으로 예상된다

위 스크립트를 실행한 data_preparation 과정은 상당히 오래 걸린다... 현재 3분 21초에 59퍼

완료 후 이제 training을 해보자
baseline과 NAFNet은 뭐가 다른거지

yml 파일을 까보니 network_g라는 설정에서 baseline의 경우 expand 값이 더 있는 것을 볼 수 있다
dw_expand는 depthwise convolution layer 입력채널을 확장하는 비율이라고 하고
ffn_expand는 feed-forward network layer의 넓이를 조정하는 비율이라고 한다
학습 돌리기 training
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 basicsr/train.py -opt options/train/GoPro/Baseline-width32.yml --launcher pytorch일단 baseline width32로 학습을 돌려보자
...일단 에러가 상당히 많이 뜬다
RuntimeError: Distributed package doesn't have NCCL built in
[W C:\cb\pytorch_1000000000000\work\torch\csrc\distributed\c10d\socket.cpp:558] [c10d] The client socket has failed to connect to [DESKTOP-]:4321 (system error: 10049 - 요청한 주소는 해당 컨텍스트에서 유효하지 않습니다.).
[W C:\cb\pytorch_1000000000000\work\torch\csrc\distributed\c10d\socket.cpp:558] [c10d] The client socket has failed to connect to [DESKTOP-]:4321 (system error: 10049 - 요청한 주소는 해당 컨텍스트에서 유효하지 않습니다.).
Traceback (most recent call last):
File "D:\MediaAILab\ImageProcessing\NAFNet\basicsr\train.py", line 305, in <module>
main()
File "D:\MediaAILab\ImageProcessing\NAFNet\basicsr\train.py", line 148, in main
opt = parse_options(is_train=True)
File "D:\MediaAILab\ImageProcessing\NAFNet\basicsr\train.py", line 54, in parse_options
init_dist(args.launcher)
File "d:\mediaailab\imageprocessing\nafnet\basicsr\utils\dist_util.py", line 21, in init_dist
_init_dist_pytorch(backend, **kwargs)
File "d:\mediaailab\imageprocessing\nafnet\basicsr\utils\dist_util.py", line 32, in _init_dist_pytorch
dist.init_process_group(backend=backend, **kwargs)
File "C:\Users\MediaAILab\.conda\envs\nafnet\lib\site-packages\torch\distributed\distributed_c10d.py", line 602, in init_process_group
default_pg = _new_process_group_helper(
File "C:\Users\MediaAILab\.conda\envs\nafnet\lib\site-packages\torch\distributed\distributed_c10d.py", line 727, in _new_process_group_helper
raise RuntimeError("Distributed package doesn't have NCCL " "built in")보아하니 파이토치의 distributed 분산 패키지를 사용하는 과정에서 소켓 포트분리 등 에러가 발생한다
현재 사용하는 로컬PC의 GPU 가용 process 수와 맞지 않아서 생기는 문제일 듯 하다

기본적으로 8개의 gpu 프로세스를 사용한다고 안내되어있다
분산 패키지는 사용해본 적이 없어 어떻게 해결해야하는지 잘 모르는데 다른 방법이 있을까?
demo?
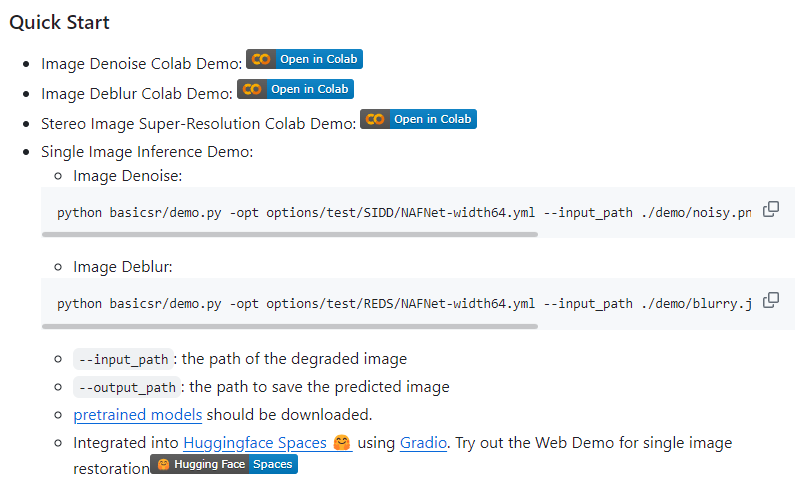
Quick Start에서 사용하는 명령어의 경우 distributed로 노드와 포트를 분리하지 않고 바로 실행하는 데모가 있다
이 방법을 시도해보자
흠... 말그대로 데모버전이라 pretrained model이 있어야하고, 데모에서는 train은 하지 않는다
torch distributed package
결국 training을 하기 위해서는 torch distributed package를
현재 사용중인 로컬 PC에서 실행할 수 있도록 세팅하는 것이 관건인 것 같다
다음에는 이 torch distributed package에 대해서 알아보고 시도해보자
'개발 · 컴퓨터공학' 카테고리의 다른 글
| NAFNet 학습환경 세팅 - torch distributed package 문제 해결 (image denoise, deblur, restoration, StereoSR) (0) | 2024.06.05 |
|---|---|
| ziplib 사용하기 - input stream없이 entry 생성하기 (0) | 2024.06.03 |
| C++ zip 압축 파일 생성 라이브러리 ziplib 시작하기 (테스트 환경세팅, libzip, libzippp, zlib) (0) | 2024.05.19 |
| libzippp 정적 라이브러리 테스트 + 어떤 방식으로는 실행시켜보기 (0) | 2024.05.15 |
| Three.js TypeScript 시작 및 초기 세팅하기 (0) | 2024.05.09 |




