
이전에 distributed package에 대한 에러가 발생하면서 훈련을 시도하지 못했다
이번에는 torch distributed package를 알아보고 에러를 해결해보자
torch distributed package
distributed라는 말 자체로만 봐도 여러 프로세스에 동시에 연산을 수행하는
병렬 프로세싱의 방법이라는 것을 알 수있다
여기서 node라는 것은 GPU를 사용하는 가상머신의 수이다
실질적으로 GPU개 몇개고 코어가 몇 개 인지와는 상관이 없다고 한다
분산 학습에 참여하는 프로세스의 수는 World Size라고 한다
한 노드에 여러 GPU를 사용할 수 있으므로 World Size는 (node 개수) x (node 당 GPU 개수)이다
Rank는 process ID를 말한다
0에서 (World Size - 1)만큼 index가 있다
--nproc_per_node
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 basicsr/train.py -opt options/train/GoPro/Baseline-width32.yml --launcher pytorch명령어 옵션에 --nproc_per_node 가 있는데
이는 node 하나에 들어가는 프로세스의 수 설정이라고 한다
보통 프로세스당 GPU 하나를 쓰게 해서, GPU수와 동일하게 설정한다고 한다
이걸 조절해볼까?
극단적으로 nproc_per_node를 1로 설정해서 해봤는데 그래도 실패했다..
뭐가 문제일까
RuntimeError: Distributed package doesn't have NCCL
NCCL이라는 GPU 통신 라이브러리를 빌드하지 않았기 때문에 발생하는 문제일 가능성이 있다고 한다
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch위 명령어로 pytorch를 재설치해보았다
pytorch 재설치로는 아직 해결되지 않는다
NCCL 이란
NCCL이라는 것은 pytorch에서 GPU 분산 학습을 하기 위한 backend의 대표적 종류이다
NCCL 사용시 운영체제
만약 GPU 분산 프로세싱을 할 때 backend로 NCCL을 사용한다면 주의할 점이 있다
바로 Linux 운영체제에서 돌아가도록 지원되기 때문에 나처럼 윈도우 기반 로컬 PC에서 돌리려 한다면 문제가 발생한다
NCCL에 대한 에러가 발생하는 것은 바로 이 문제였지 싶다
NCCL 대안책 gloo
그래서 window OS에서 GPU 분산 통신을 위해서는 'gloo'라는 라이브러리를 쓴다고 한다
코드를 뜯어 backend를 gloo로 변경해보자
Baseline-GoPro-width32.yml
# dist training settings
dist_params:
backend: nccl
port: 29500위 yml 파일에서 backend를 nccl말고 gloo로 변경하고
Traceback (most recent call last):
File "D:\MediaAILab\ImageProcessing\NAFNet\basicsr\train.py", line 305, in <module>
main()
File "D:\MediaAILab\ImageProcessing\NAFNet\basicsr\train.py", line 148, in main
opt = parse_options(is_train=True)
File "D:\MediaAILab\ImageProcessing\NAFNet\basicsr\train.py", line 54, in parse_options
init_dist(args.launcher)
File "d:\mediaailab\imageprocessing\nafnet\basicsr\utils\dist_util.py", line 21, in init_dist
_init_dist_pytorch(backend, **kwargs)
File "d:\mediaailab\imageprocessing\nafnet\basicsr\utils\dist_util.py", line 32, in _init_dist_pytorch
dist.init_process_group(backend=backend, **kwargs)
File "C:\Users\MediaAILab\.conda\envs\nafnet\lib\site-packages\torch\distributed\distributed_c10d.py", line 602, in init_process_group
default_pg = _new_process_group_helper(
File "C:\Users\MediaAILab\.conda\envs\nafnet\lib\site-packages\torch\distributed\distributed_c10d.py", line 727, in _new_process_group_helper
raise RuntimeError("Distributed package doesn't have NCCL " "built in")
에러를 보니까 basicsr/utils/dist_util.py의 init_dist함수에서 backend 설정을 바꾸어 주어야 하는 것 같다
def init_dist(launcher, backend='nccl', **kwargs):
if mp.get_start_method(allow_none=True) is None:
mp.set_start_method('spawn')
if launcher == 'pytorch':
_init_dist_pytorch(backend, **kwargs)
elif launcher == 'slurm':
_init_dist_slurm(backend, **kwargs)
else:
raise ValueError(f'Invalid launcher type: {launcher}')여기에 nccl로 backend가 설정되어있다 이를 바꾸어보자
gloo로 실행하기
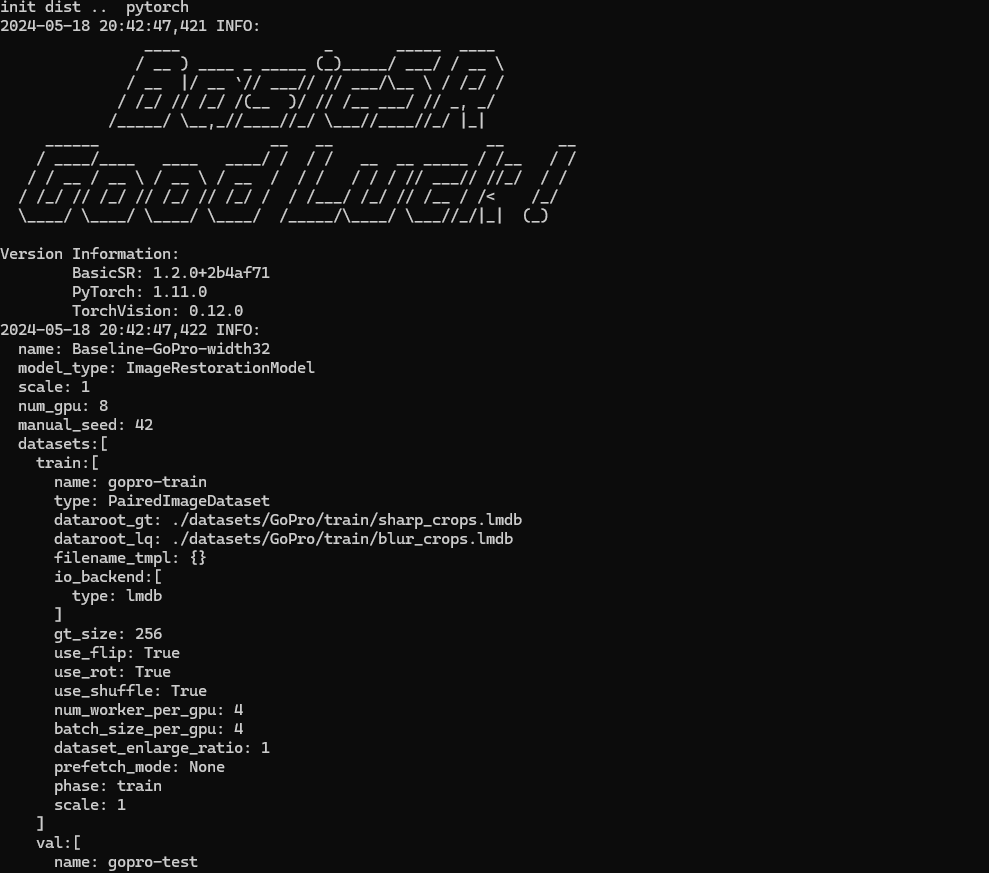
이렇게 뭔가 basicSR이 실행되었다가
또 다른 에러가 뜬다
ValueError
ValueError: Keys in lq_folder and gt_folder are different.
이번엔 value error가 떴다
이는 해당 folder들에 지정된 키의 파일들이 없어서 발생하는 문제라고 한다
아무래도 dataset으로 사용하는 lmdb 파일이 일치하지 않아서 발생하는 문제 같은데..
datasets:
train:
name: gopro-train
type: PairedImageDataset
dataroot_gt: ./datasets/GoPro/train/sharp_crops.lmdb
dataroot_lq: ./datasets/GoPro/train/blur_crops.lmdb
filename_tmpl: '{}'
io_backend:
type: lmdb
gt_size: 256
use_flip: true
use_rot: true
# data loader
use_shuffle: true
num_worker_per_gpu: 4
batch_size_per_gpu: 4
dataset_enlarge_ratio: 1
prefetch_mode: ~
val:
name: gopro-test
type: PairedImageDataset
dataroot_gt: ./datasets/GoPro/test/target.lmdb
dataroot_lq: ./datasets/GoPro/test/input.lmdb
io_backend:
type: lmdb아무래도 위 option 코드의 dataroot 경로의 lmdb 폴더 경로들을 확인해봐야겠다
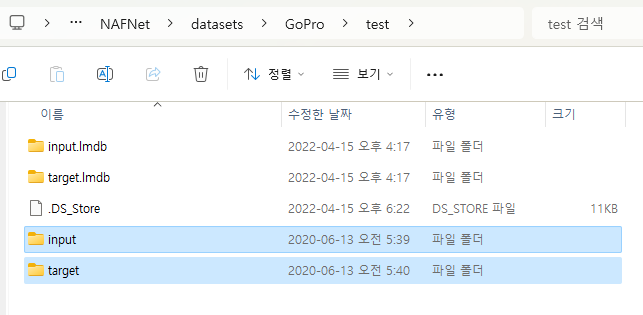
input와 target 폴더가 test가 아니라 train안에 있길래 test로 가져왔다
이게... 아닌가?
https://github.com/megvii-model/HINet/issues/15
Image Deblur - Custom dataset Error · Issue #15 · megvii-model/HINet
Thanks for writing a good paper. I have data[input,target] that I have. Now ./datasets/ ./datasets/GoPro/ ./datasets/GoPro/train/ ./datasets/GoPro/train/input/ ./datasets/GoPro/train/target/ ./data...
github.com
나와 비슷한 상황에 처한 이슈를 찾았다
에러를 보아하니 lmdb의 데이터가 잘못 되었을 가능성을 고려하여,
lmdb를 정상작동하는 데이터로 따로 가져와서 실행해보았다
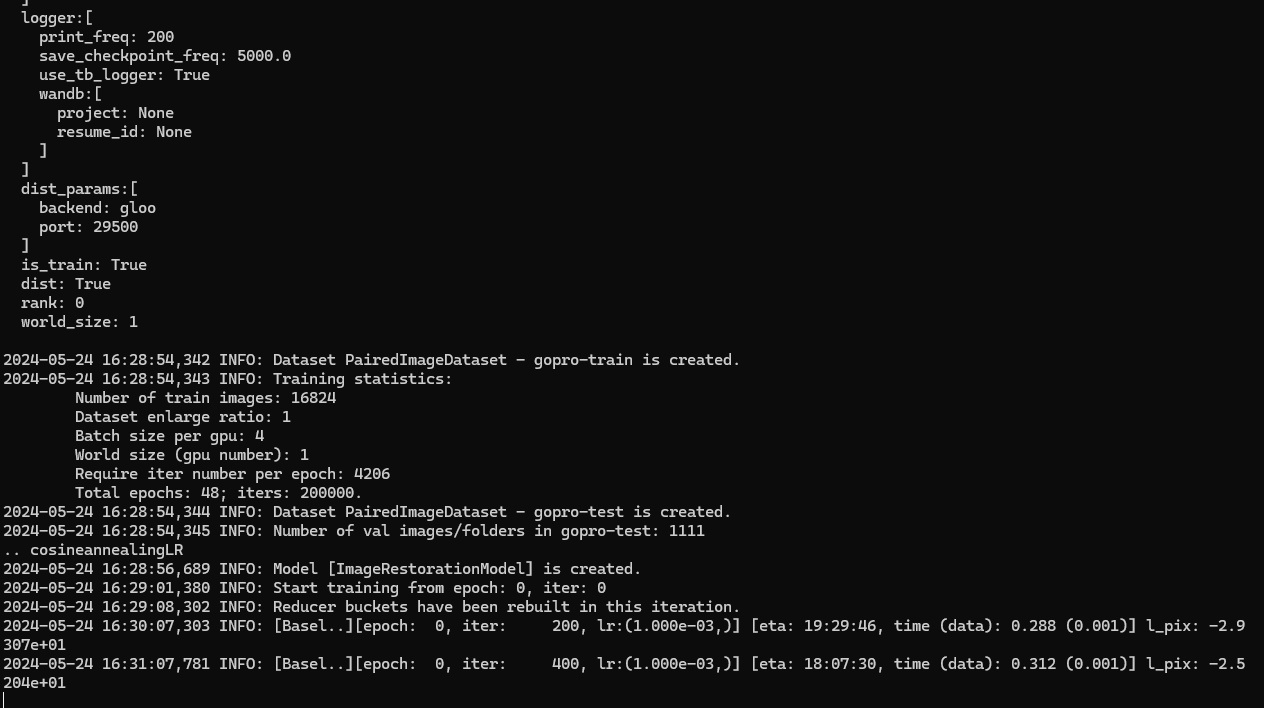
meta.txt 경로가 잘못되었다는 에러 때문에 파일 경로를 좀 수정해주고 해보니... 된다?
결국 lmdb의 문제였나 싶다
올바른 dataset lmdb 데이터셋 세팅
파일을 이것저것 해보다가 헷갈려서 정상적으로 돌아가는 파일 구조를 정리 해보자
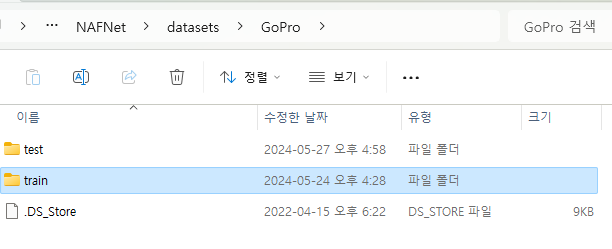
Gopro의 test와 train 폴더 각각에 어떻게 분리할지가 관건이다

생각해보니 test의 경우 evaulation을 할 때 사용되므로 훈련에서는 데이터셋을 넣을 필요가 없는 것 같다
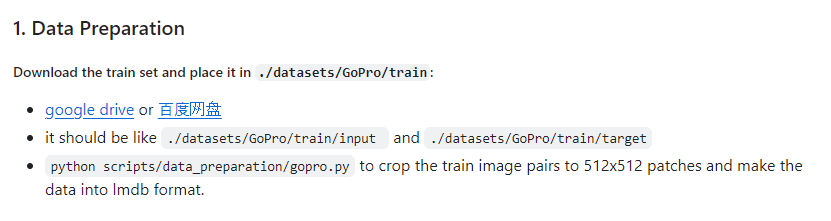
메뉴얼에는 train폴더에 input과 target 데이터셋을 넣는 것으로 확인된다

왼쪽은 blur 데이터 오른쪽은 sharp 데이터이다
위에서 말한 input과 target은 이름이 아니라
각각 input이 되는 blur 데이터와 target으로 사용되는 sharp 데이터를 말하나?

파일 경로가 잘못되면 이런 에러로 확인 된다
일단 train경로에는 blur 밑 sharp 데이터셋이 있어야할 것 같다

test 경로에도 파일이 필요한 듯 하다
input과 target을 필요로한다
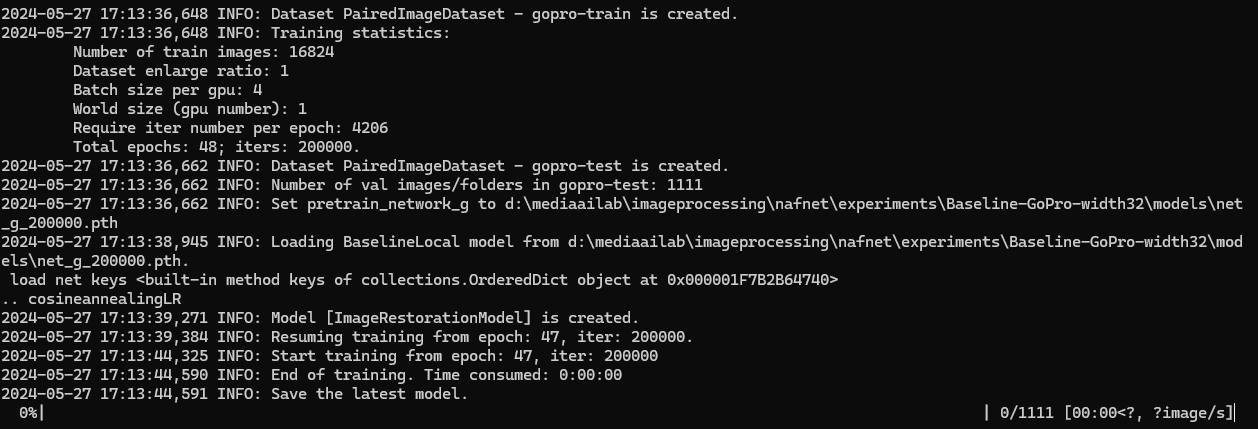
학습이 정상 시작되었다
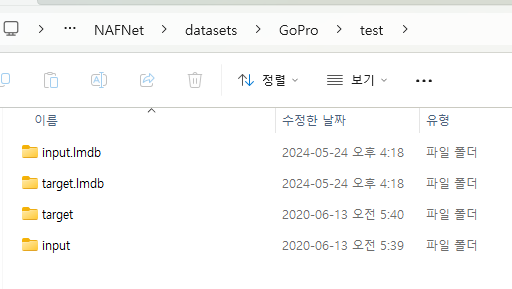
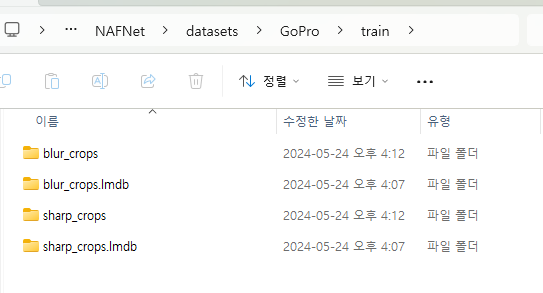
정리하면
test 폴더에는 input과 target 데이터를 lmdb로 만든 것
train 폴더에는 blur_crops, sharp_crops를 lmdb로 만든 것
이렇게 필요하다
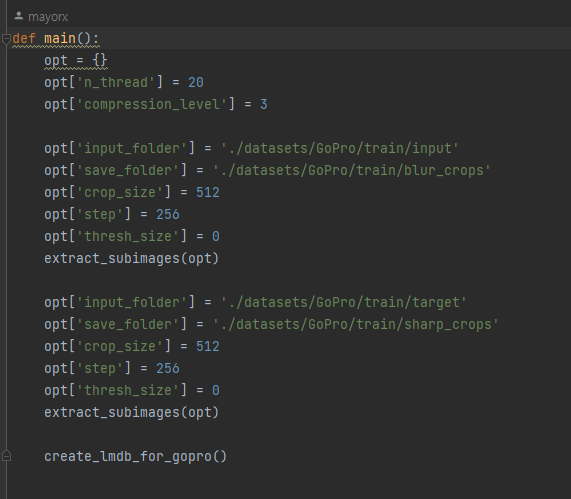
참고로 blur_crops와 shar_crops의 경우 input과 target으로 gopro.py 스크립트를 이용하면 생성된다
lmdb도 마찬가지. 헷갈리지 말자
학습하기
이제 세팅을 완료하였으니 학습시켜보자
option --nproc_per_node 로 GPU 분산 처리에 사용될 프로세스(world)를 조절할 수 있다
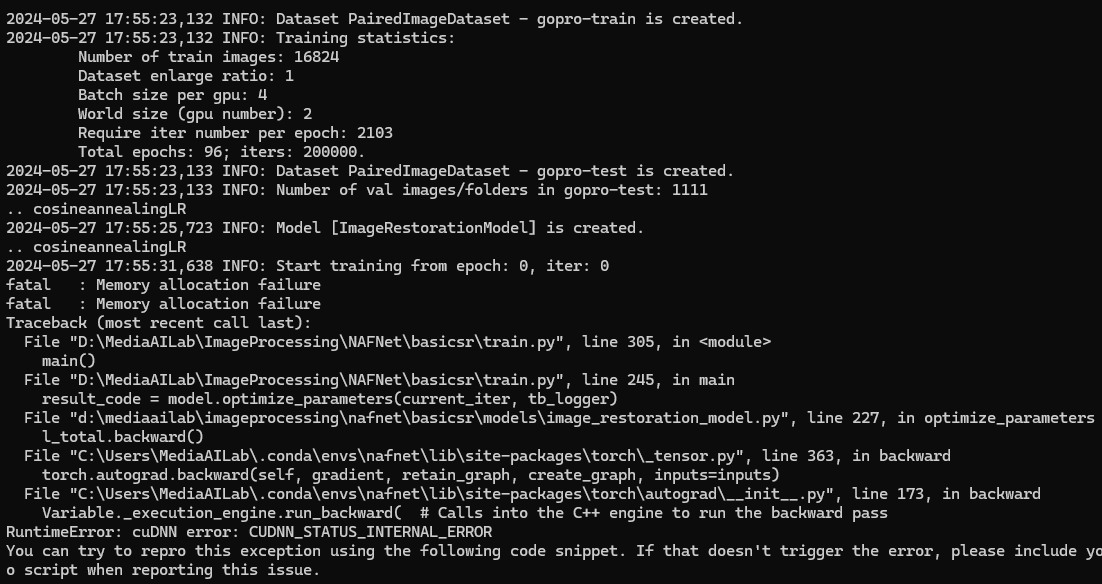
python -m torch.distributed.launch --nproc_per_node=2 --master_port=4321 basicsr/train.py -opt options/train/GoPro/Baseline-width32.yml --launcher pytorch
위와 같이 2개의 프로세스로 해도 로컬 PC에서는 메모리가 부족해서 할당 실패가 된다
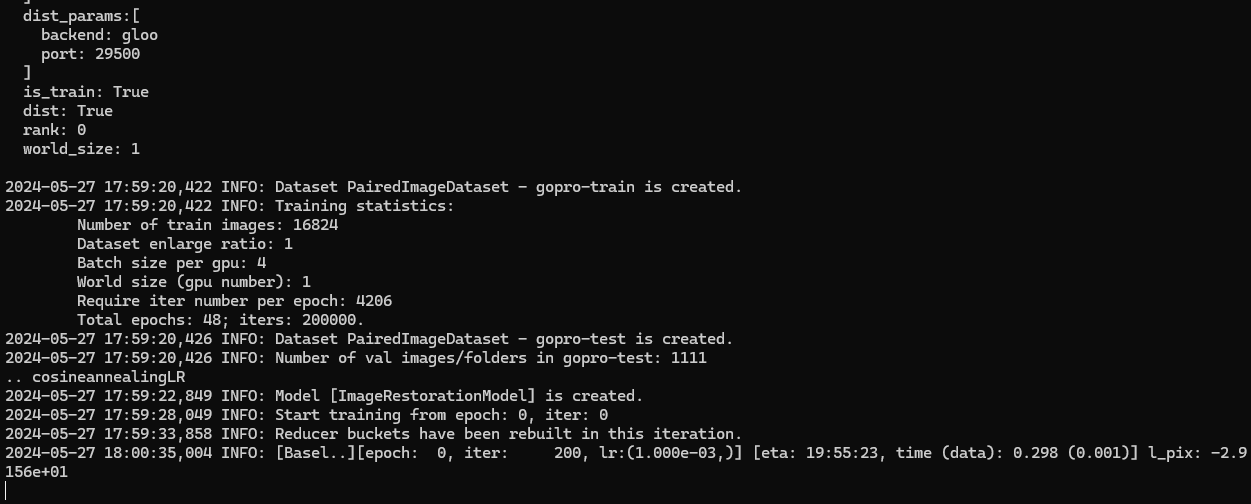
서버를 사용하지 않고 내 PC에서는 최소한의 프로세스 1개로만 실행가능할 것 같다
학습이 안료된 데이터를 가지고 다음에는 evaluation 평가를 해보고
더 나은 성능을 위해 normalization을 수정해서 시도해보자




