Waveforms
시간이 지남에 따라 바뀌는 소리의 형태
waveform은 시간 길이를, amplitude는 진폭을 말한다.
waveform은 한 번에 여러 interval간 관계를 볼 수 있고, 동기화할 때 유용하다
하지만 물리적인 파동 정보만으로는 지각이 가능한게 아니다 (소리가 섞여도 인지, 공간 인지 등)
Digitization
Sampling
samppling theorm : 소리를 샘플링할 때 최소 40kHZ의 sampling rate가 보장되어야 들을 수 있다
따라서 CD의 경우 44.1kHZ이고 인터넷 오디오는 이 1/2배인 22.05kHZ를 사용한다
DAT의 경우 48kHZ
Jitter
timing 변동으로 인해서 발생하여, 복원된 신호에 noise를 유발한다
Quantization
Dithering
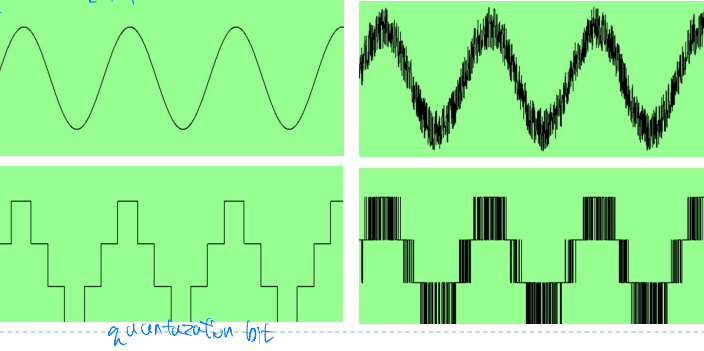
샘플링 전에 랜덤한 노이즈를 도입한다
조밀한 16bit에서 bit를 줄이고, 노이즈를 통해서 quantization level 사이에서 교차함으로써 smooth하게 만든다
Sound Processing
noise gate
threshold를 이용하여 샘플에서 특정 임계값 이하의 노이즈를 제거한다
이때 진폭이 낮은 시퀀스가 시작되기 전 경과해야하는 최소 시간 지정
문제점
사람은 노이즈와 신호를 구분할 수 있지만 컴퓨터는 못하므로 오히려 original noise보다 산만할 수 있다
Discrete Fourier Transform
$$e^{i \omega t} = \cos(\omega t) + i \sin(\omega t)$$
위 푸리에 변환에서 t의 계수가 커지면 진폭이 달라지고, 주기(frequency)가 커진다
input signal \(x_n\)을 많이 더할 수록 high frequency의 퀄리티가 구체화된다
t가 작은 부분은 low frequency component
t가 큰 부분은 high frequency component
filtering
filtering으로 특정 부분을 제외하는 방법이 있는데
low pass filter는 low frequency만 통과시키고 high frequency는 block한다
(전반적인 큰 모양만 유지)
반대로 high pass filter는 low frequency를 block한다
(큰 모양은 잃고 자잘한 소리가 남음)
특정 frequency component만을 block하는 filter
band reject filter
특정 frequency component만을 pass
band pass filter
Compression
자연의 오디오 데이터는 복잡하고 예측하기 힘들기 때문에
데이터 퀄리티를 떨어뜨린 손실 압축 방법이 필요하다
소리와 이미지는 인식하는 방법이 다르므로, 이미지 압축과는 압축방법이 다르다
Speech Compression
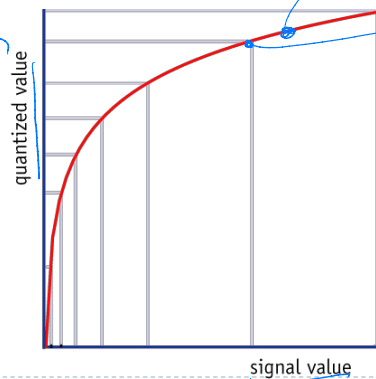
quantized value는 사람이 인지하는 감도의 정도이다
비선형 그래프로 그려지는데
이는 소리가 작으면 작은 변화에 대한 감도가 크고
소리가 크면 변화에 둔감해진다
압축을 하게 되면 연속적인 비선형 그래프에서
주어진 bit 만큼의 quantization level로 value가 줄여져서 용량을 아낀다
소리가 크면 quantization level에 따라 signal value 간격이 멀리 떨어져있어서 압축시 티가 안나지만
소리가 작으면 quantization level에 따른 signal value 간격이 가까워서 압축시 변화가 느껴진다
Differential Pulse Code Modulation (DPCM)
video inter-frame 압축과 비슷
다음 샘플의 예측 값을 계산하고, 예측 값과 실제 값 간 차이를 저장한다
DPCM은 차이가 sampling보다 적은 bit수로 저장될 수 있는 경우에 효과적인 압축 방법이다
Adaptive Differential Pulse Code Modulation (ADPCM)
quantized difference를 저장하는데 사용되는 step size를 동적으로 변화시킨다
Perceptually-Based Compression
지각에 영향을 미치지 않는 신호 데이터를 식별해서 제거한다
사람의 귀와 뇌는 소리 파동에 단순히 반응하지 않으므로 청각 심리 모델이 필요하다

hearing threshold는 너무 조용해서 들리지 않는 소리로 한다
주파수 소리가 너무 낮거나 높은 경우는 사람이 더 잘 인지하지 못하므로 더 커야한다
threshold 아래의 소리는 유지하지 않는다

더 큰 소리는 더 작은 소리를 가릴 수 있다
더 큰 소리는 그 주변의 약간의 범위의 소리도 가려질 수 있다
masking은 큰 소리 영역에서 threshold of hearing 곡선을 수정해서 적용한다
masking sound는 quantize를 거칠게 한다
Compression Algorithm
filter를 사용해서 신호를 여러 주파수 대역으로 분할한다 (보통은 32개의 대역 사용)
각 대역의 평균 값과 청각심리 모델을 기반으로 masking level을 계산한다
각 대역에 대해 단일 값으로 masking 곡선을 근사한다
신호가 masking level 보다 낮으면 제거한다
아니면 quantization noise를 masking할 최소한의 bit를 사용해서 quantize한다
MP3
MP3는 MPEG-1, Layer 3를 줄인 말이다
MPEG-1, MPEG-2에는 세 가지 layer의 오디오 압축이 있다
MPEG-3은 존재하지 않는다
layer 1~3에서 인코딩 과정이 복잡해지면 동일 품질 데이터 속도는 감소한다
높은 품질에서는 10:1의 압축 비율을 가진다
Variable Bit Rate coding(VBR)로 bit rate를 변경한다
Advanced Audio Coding (AAC)
MPEG-2 표준에 정의되어서 확장 후 MPEG-4에 포함되었다
이전 표준과의 하위 호환성은 없다
MP3보다 높은 압축 비율과 낮은 bit rate를 가진다
동일한 bit rate에서는 MP3보다는 품질이 낫다
Speech Recognition
speech recognition(음성 인식)은 음향 신호를 단어 문자열로 매핑하는 작업이다
speech under standing(음성 이해)은 음향 신호를 발음해서 의미를 매핑하는 작업
어떤 소리를 발음했는지
소리가 어떤 단어를 표현하는지
단어로 어떤 의미를 표현하려 했는지
~를 아는 것이다
What's hard about that
말하기의 ambiguity 문제들
Digitization : 아날로그 신호를 디지털 표현으로 변환
Signal processing : 배경 소음에서 음성을 분리
Phonetics : 음성학. 음간 음성의 변이성
Phonology : 음운론. 개별 소리 구별 인식
Lexicology and syntax : 어휘론 구문론. 동음이의어를 구별하고 연속 음성의 특징을 구분
Syntax and pragmatics : 구문론 화용론. 운율적 특징 해석
Pragmatics : 화용론. 발음 오류(비유창성) 필터링
Formants

acoustic resonance(음향 공명)
spectrogram을 사용해서 frequency spectrum에서 peak로 측정된다
F1, F2등 위치는 모음에 따라 다르다
★ Speech Recognition Architecture
노이즈 채널 모델 구현의 문제
어떤 문장의 의미가 맞는지 확률에 따라서 결정하거나 A* 알고리즘을 사용한다
현재 음성 인식기
- 잠재적인 원본 문장의 방대한 공간을 탐색한다
- 해당 문장을 생성할 확률이 가장 높은 문장을 선택한다
- 그래서 단어의 확률을 표현하는 모델을 사용한다
- N-gram과 HMM 모델을 적용한다
목표 : 주어진 음향 입력 O에 대해 언어 L의 모든 문장에서
가장 가능성이 높은 문장은?
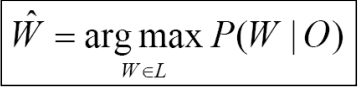
구하려는 W는 word sequence 즉 문장으로,
위 식은 발음된 O에 대해 주어진 입력이 의미하는 문장이 매핑될 수 있는 확률이다

여기에 Bayes' rule을 이용하여 표현한다

\(P(W|O)\) 는 발음 이후 확률 posterior probability
\(P(O|W)\) 는 같은 단어 W에 대한 발음 acoustic model
정확하지 않은 Observation이라서 likelihood
\(P(W)\) 는 language model에서 단어가 나올 발음 이전 확률 prior probability
Speech Recognition System의 세 단계
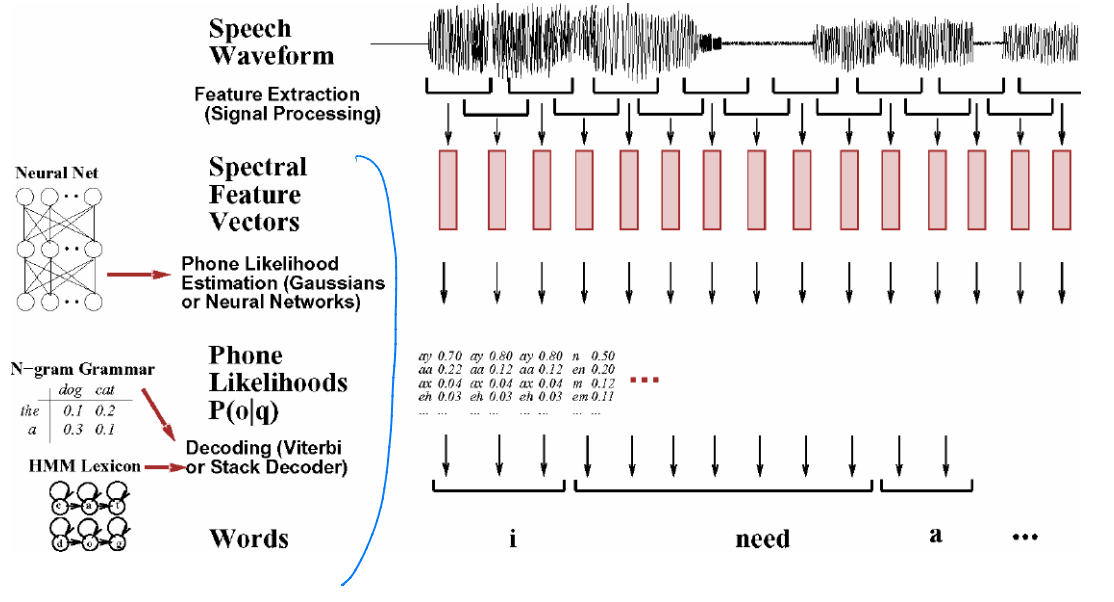
1. 신호 처리 특징 추출 단계
waveform을 프레임으로 나눈다
waveform을 spectral feature로 바꾼다
2. subword 나 phone 인식 단계
개별 음성을 인식한다
3. decoding 단계
입력을 생성할 가능성이 가장 높은 단어 문장을 찾는다




