NAFNet 학습된 모델 평가하기

해당 방법으로 evaluation을 진행해보자


우선 experiments/pretrained_models 경로에 학습완료된 모델 pth 파일을 넣고
이름을 데이터셋에 맞게 바꿔준다
여기서는 GoPro witdth32로 학습시켰으므로 NAFNet-GoPro-width32.pth 라고 한다
python -m torch.distributed.launch --nproc_per_node=1 --master_port=4321 basicsr/test.py -opt ./options/test/GoPro/NAFNet-width32.yml --launcher pytorch
실행해보니 에러가 나는데

options/test/GoPro/NAFNet-width32.yml에서 백엔드를 수정해보자

그래도 실패네..
RuntimeError: Error(s) in loading state_dict for NAFNetLocal
RuntimeError를 보면 state와 관련해서 에러가 난 것 같다
state_dict에 key들이 없어서 생기는 문제라고 하는데
잘못된 모델을 가져왔다보다
latest가 아니라 step을 2,000,000까지 진행시킨 모델을 가져와야했나
바꿔서 실행해보니 이것도 아닌데..
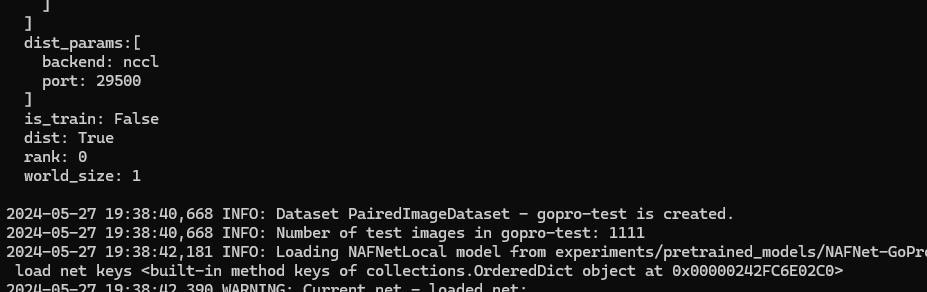
다시보니 로그에 backend가 nccl로 되어있는데 이제 문젠가?
분명 yml option 파일에서는 backend를 gloo로 잘 바꿨는데
근데 잘 보니 내가 학습시킨 option은 baseline width32인데
평가는 NAFNet width32 로 하고 있었다
python -m torch.distributed.launch --nproc_per_node=1 --master_port=4321 basicsr/test.py -opt ./options/test/GoPro/Baseline-width32.yml --launcher pytorch
이걸로 다시 해보자
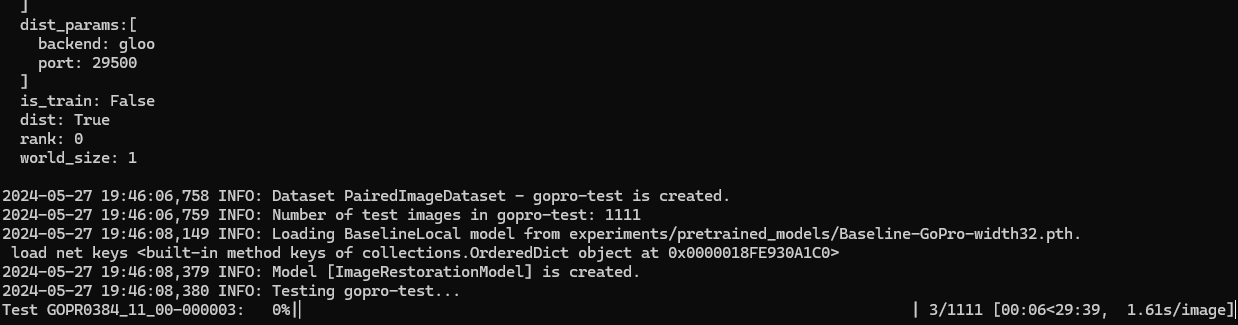
이제 evaluation이 잘 되는 것 같다
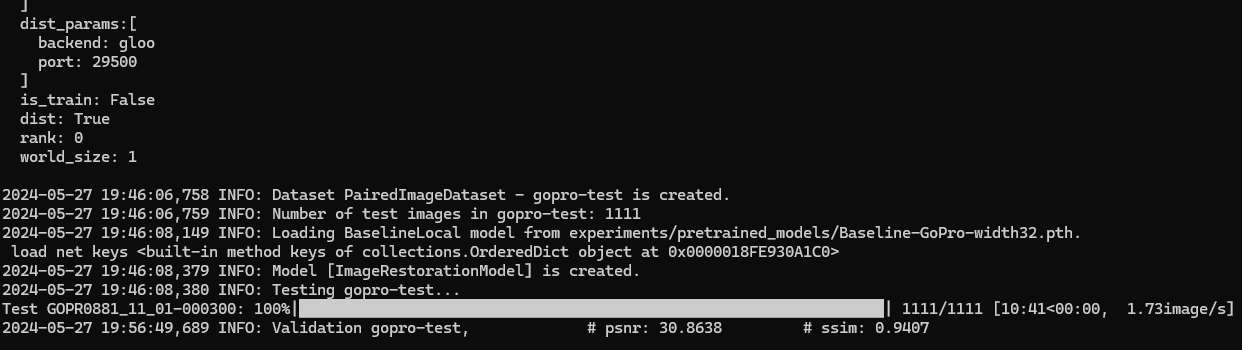
평가를 진행시키고 결과를 보자
평가 완료
평가가 완료되면 results 폴더에 결과물이 생긴다
결과물보단 중요한 것은 psnr와 ssim이다
아무것도 취하지 않은 기본 상태의 평가 결과
psnr : 30.8738
ssim : 0.9407
이 나왔다
성능 향상하기 - normalization 변경하기
이제 normalization을 수정해서 성능을 향상시켜보자
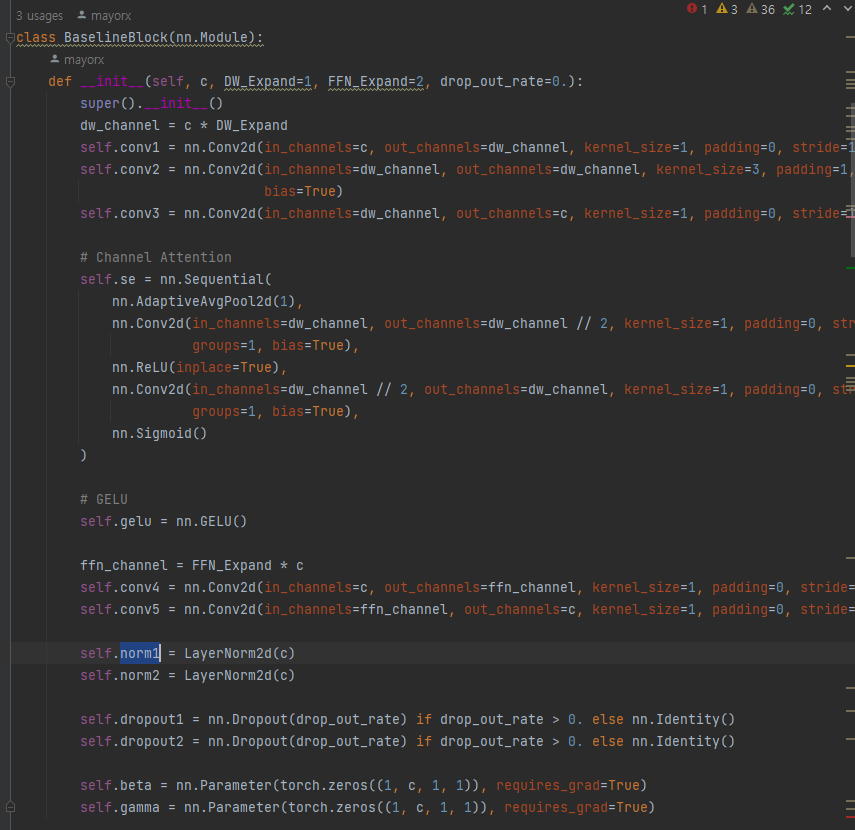
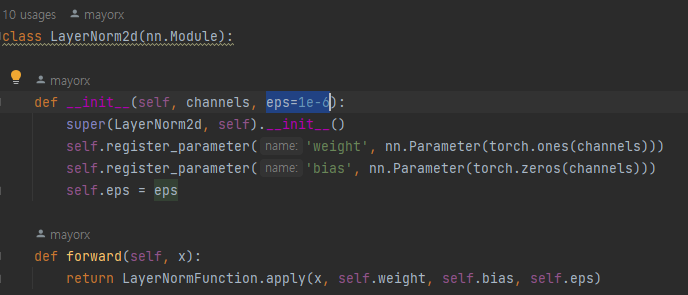
LayerNrom2d 함수의 eps값을 바꾸어서 학습해보자
흠... 좀 알아봤는데 위 방법으로 하는게 아니고 normalization의 유형을 바꾸어서 테스트 해보는 것이다
Group Normalization
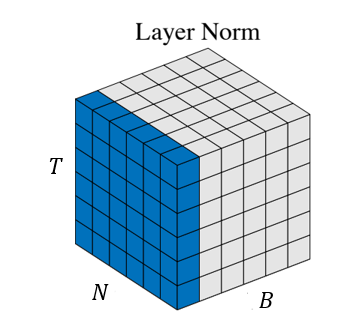
현재는 layer normalization을 사용하고 있다면
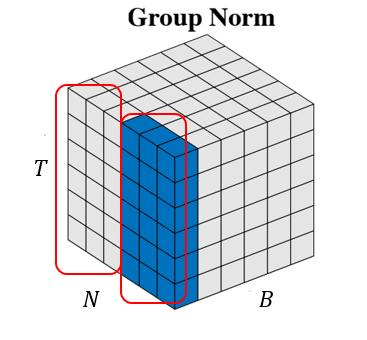
Group normalization으로 바꾸어서 사용해본다
class GroupNorm2d(nn.Module):
def __init__(self, channels, eps=1e-6):
super(GroupNorm2d, self).__init__()
self.gn = nn.GroupNorm(2, channels, eps=1e-08)
# self.register_parameter('weight', nn.Parameter(torch.ones(channels)))
# self.register_parameter('bias', nn.Parameter(torch.zeros(channels)))
# self.eps = eps
def forward(self,x):
return self.gn(x) #[B, N, T] -> [B, N, T]코드는 위와 같이 GroupNorm2d 함수를 arch_util.py에 새로 만들어주고
# Layer normalization
# self.norm1 = LayerNorm2d(c)
# self.norm2 = LayerNorm2d(c)
# Group normalization
self.norm1 = GroupNorm2d(c)
self.norm2 = GroupNorm2d(c)기존 Baseline_arch.py에 있던 normalization을 layer가 아니라 group으로 바꾼다
class InstanceNorm2d(nn.Module):
def __init__(self, channels, eps=1e-6):
super(InstanceNorm2d, self).__init__()
self.istanceNorm = nn.GroupNorm(channels, channels, eps=1e-08)
# self.register_parameter('weight', nn.Parameter(torch.ones(channels)))
# self.register_parameter('bias', nn.Parameter(torch.zeros(channels)))
# self.eps = eps
def forward(self,x):
return self.istanceNorm(x) #[B, N, T] -> [B, N, T]같은 방법으로 이번에는 Instance Normalization으로 바꾸어 학습을 시켰다
class BatchNorm2d(nn.Module):
def __init__(self, channels, eps=1e-6):
super(BatchNorm2d, self).__init__()
self.bn = nn.BatchNorm2d(channels)
def forward(self,x):
return self.bn(x)마지막으로 Batch Normalization으로 학습을 시켰다
depthwise separable convolution
def __init__(self, c, DW_Expand=1, FFN_Expand=2, drop_out_rate=0.):
super().__init__()
dw_channel = c * DW_Expand
self.conv1 = nn.Conv2d(in_channels=c, out_channels=dw_channel, kernel_size=1, padding=0, stride=1, groups=1, bias=True)
self.conv2 = nn.Conv2d(in_channels=dw_channel, out_channels=dw_channel, kernel_size=3, padding=1, stride=1, groups=dw_channel,
bias=True)
self.conv2_dw = nn.Conv2d(in_channels=dw_channel, out_channels=dw_channel, kernel_size=3, padding=1, stride=1, groups=dw_channel, bias=True)
self.conv2_pw = nn.Conv2d(in_channels=dw_channel, out_channels=dw_channel, kernel_size=1, padding=0, stride=1, groups=1, bias=True)
self.conv3 = nn.Conv2d(in_channels=dw_channel, out_channels=c, kernel_size=1, padding=0, stride=1, groups=1, bias=True)
...convolution에 depthwise와 pointwise를 추가한다
def forward(self, inp):
x = inp
x = self.norm1(x)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv2_dw(x) # depthwise
x = self.gelu(x)
x = self.conv2_pw(x) # pointwise
x = x * self.se(x)
x = self.conv3(x)
x = self.dropout1(x)
y = inp + x * self.beta
x = self.conv4(self.norm2(y))
x = self.gelu(x)
x = self.conv5(x)
x = self.dropout2(x)
return y + x * self.gammaforward 함수에서 GELU 함수의 전후에 depthwise와 pointwise convolution을 배치한다
# Batch normalization
self.norm1 = BatchNorm2d(c)
self.norm2 = BatchNorm2d(c)normalization은 batch로 해주었다
validation 표시
Baseline-width32.yml
# validation settings
val:
save_img: true
grids: false
val_freq: 1000val key에다가 val_freq를 설정해주면 해당 iteration개수마다 validation을 표시해준다
기본적으로는 빠져있는 option인데
train.py
# validation
if opt.get('val') is not None and (current_iter % opt['val']['val_freq'] == 0 or current_iter == 1000):
# if opt.get('val') is not None and (current_iter % opt['val']['val_freq'] == 0):
rgb2bgr = opt['val'].get('rgb2bgr', True)
# wheather use uint8 image to compute metrics
use_image = opt['val'].get('use_image', True)
model.validation(val_loader, current_iter, tb_logger,
opt['val']['save_img'], rgb2bgr, use_image )
log_vars = {'epoch': epoch, 'iter': current_iter, 'total_iter': total_iters}
log_vars.update({'lrs': model.get_current_learning_rate()})
log_vars.update(model.get_current_log())
msg_logger(log_vars)train 스트립트의 validation부분을 보면 해당 key값을 사용할 수 있게 되어있다
Normalization으로 layner
soon...
'개발 · 컴퓨터공학' 카테고리의 다른 글
| 취업 취준 코딩테스트 준비! 자주 나오는 유형 알아보기 (기업 코테) (18) | 2024.07.23 |
|---|---|
| NeRF(Neural Radiance Fields)논문에 대해서 알아보자 (1) | 2024.07.17 |
| 쉐이더가 byte 형태로 되어있다? precompiled binary shader (0) | 2024.07.09 |
| 천 모양의 fabric mesh cutting 자르는 방법 탐색하기 + stitching 붙이기(재단하기, 재봉하기) (0) | 2024.07.06 |
| 초해상도 ESRGAN 논문 요약과 훈련 결과 (0) | 2024.06.30 |




