Segmentation
Gestalt Theory
전체는 부분의 합보다 크다
부분 간의 관계가 새로운 feature를 만들어낼 수 있다
Gestalt properties
Similarity 유사성
Symmetry 대칭성
Common Fate 단결성
Proximity 근접성
Clustering Method
K-Means Clustering
initialization
K개의 범주와 특징 공간의 N개의 점이 주어진다. K개의 점을 무작위로 선택하여 초기 cluster 중심(means)으로 설정하고 다음 절차를 반복한다
1. N개의 각 점 \(x_j\)를 가장 가까운 \(m_i\) cluster에 할당한다 (이때 cluster가 비어있으면 안되다)
2. 각 cluster의 구성 점들로부터 평균 \(m_i\)를 다시 계산한다
3. 어떤 mean도 변경되지 않으면 중단한다
장점
- 단순하고 계산이 빠르다
- cluster 내 squared error의 local minimum으로 수렴한다
단점
- 초기 중심에 민감하다
- outlier에 민감하다
- 구형 cluster만 감지한다
- mean을 계산할 수 있어야한다
Probabilistic Clustering
K-means에서는 점 x가 cluster m에 속할 확률이나 cluster의 형태 등을 알 수 없다
idea
데이터를 여러 점으로 취급하는 대신, 모두 연속적인 함수에서 샘플링 된 것으로 가정한다
이 함수를 generative model 이라고 한다
매개변수 벡터 \(\theta\)로 정의된다
Mixture of Gaussians
generative model 중 하나로 데이터가 여러 gaussian 분포로부터 샘플링 된 것으로 가정하고, 각 cluster가 하나의 gaussian blob으로 나타내진다
Expectation Maximization (EM)
likelihood function을 최대화하는 block 매개변수 \(\theta\)를 계산한다
1. E-step : 현재 blob의 추정을 바탕으로 각 점의 소유권을 계산한다
2. M-step : 소유권 확률을 바탕으로 blob을 갱신하여 가능도 함수를 최대화한다
3. 수렴할 때까지 E-step과 M-step을 반복한다
Mixture of Gaussian과 EM의 장단점
장점
확률적 해석이 가능하다
데이터 포인트와 cluster 간의 부드러운 할당이 가능하다
generative model로 새로운 데이터 포인트를 예측할 수 있다
상대적으로 간결한 저장이 가능하다
단점
local minima 문제
K-mean과 달리 초기화가 필요하다
구성 요소의 수를 알아야한다
generative model을 선택해야 한다
수치 문제는 종종 문제가 된다
★ Mean‐Shift Segmentation
clustering 기반 세분화를 위한 기법이다
1. 랜덤 시드와 윈도우 W를 초기화한다
2. W의 무게중심(mean)을 계산한다
3. 검색 윈도우를 평균으로 이동한다
4. 수렴할 때까지 2부터 반복한다
mean-shift clustering
feature를 찾고 개별 픽셀 위치에서 윈도우를 초기화한다
각 윈도우에 대해서 수렴할 때까지 mean shift를 수행한다
동일한 peak 또는 mode 근처의 윈도우를 병합한다
★ 장점
- 일반적이고 응용 프로그램에 독립적이다
- 모델에 구애받지 않고 데이터 cluster에 대해서 prior shape를 가정하지 않는다
- 단일 매개변수 window size만 사용하고 k-means와 달리 물리적 의미를 가진다
- 가변적인 mode를 찾을 수 있다
- outlier에 강하다
★ 단점
- 출력이 window size에 따라 다르다
- windoe size선택이 쉽지 않다
- 계산 비용이 상대적으로 높다
- 특징 공간의 차원이 증가할수록 성능이 좋지 않다
Histogram-based segmentation
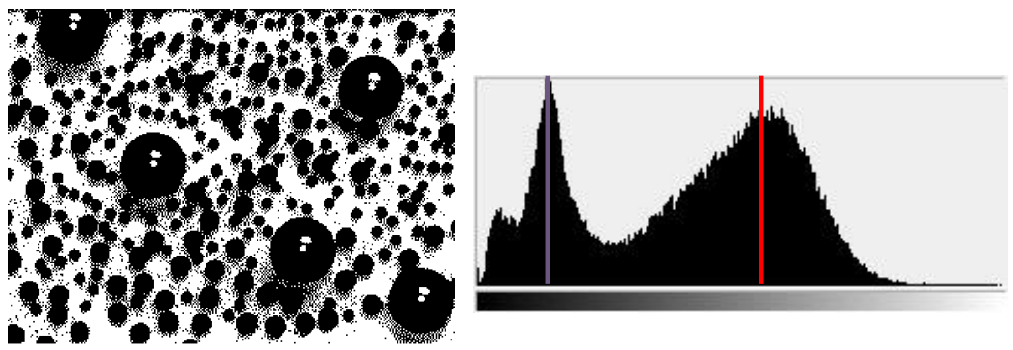
이미지를 K개 segment로 나눈다
색상의 수를 K로 줄이고 각 픽셀을 가장 가까운 색상에 매핑한다
Images as Graphs
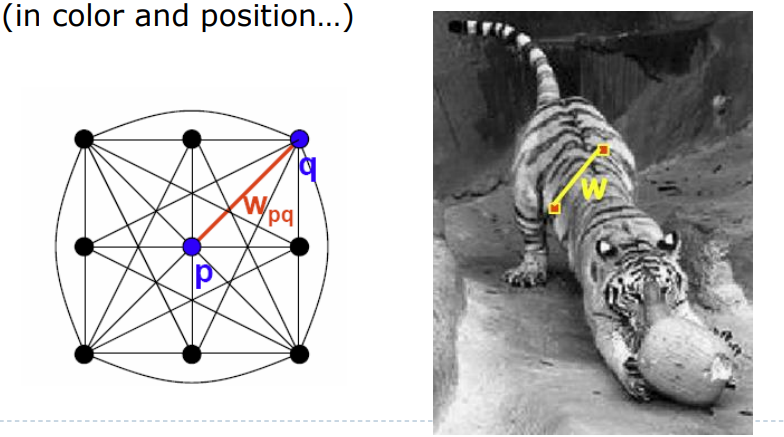

edge에 weight를 가진 fully-connected graph를 segment로 나눈다
세그먼트 간 교차하는 weight가 낮은 링크를 삭제한다
유사한 픽셀은 같은 세그먼트에 위치하고 유사하지 않으면 다른 세그먼트에 위치한다




