728x90
반응형
- 자료 구조의 분류
- 선형 구조 : 선형 리스트(배열), 연결 리스트, 스택, 큐, 데크
- 비선형 구조 : 트리, 그래프
연결 리스트 (Linked List)
- 노드의 포인터 부분을 서로 연결
- 노드 삽입, 삭제 작업 용이
- 기억공간이 연속적이지 않아도 저장가능
- 링크(포인터)가 필요하므로 기억공간 이용 효율이 안좋음
- 접근 속도 느림
- 중간 노드가 끊어지면 다음 노드 찾기 힘듬
- 희소 행렬를 표현시 기억장소 절약
스택 (Stack)
- 리스트의 한쪽으로만 삽입, 삭제
- LIFO : Last In First Out 방식
- TOP : 마지막 삽입 자료 위치, 스택포인터
- Bottom : 가장 밑바닥
- PUSH : 자료 입력
- POP : 자료 출력
스택의 용도
- 부프로그램 호출 시 복귀주소 저장
- 함수 호출 순서 제어
- 인터럽트 발생 시 복귀주소 저장
- 후위 표기법 산술식 연삭
- 0 주소지정방식 명령어 자료 저장소
- 재귀 프로그램 순서 제어
- 컴파일러 언어 번역
큐 (Queue)
- 선형 리스트 한쪽에서 삽입, 다른 쪽에서 삭제
- 시작(Front, Head)과 끝(Rear, Tail) 두 포인터
- FIFO : FIst In Fist Out
- Front 포인터 : 가장 먼저 삽입된 자료 포인터
- Rear 포인터 : 가장 마지막에 삽입된 자료 포인터
Queue 이용 예
- 서비스 순서 대기 행렬 처리
- 운영체제 작업 스케줄링
데크 (Deque)
- 삽입 삭제가 양쪽에서 가능
- Double Ended Queue
- 입력제한 : 입력이 한쪽에서만 발생
출력제한 : 출력이 한쪽에서만 발생 - 입력 제한 데크 : Scroll
- 출력 제한 데크 : Shelf
트리(Tree)
- 정점(Node)과 선분(Branch)로 사이클이 없는 그래프
- 계보, 연산 수식, 조직 구조, Heap 등에 적합

- 노드(Node) : 트리의 기본 요소.
- 근 노드(Root Node) : 트리의 맨 위 노드
- 디그리(Degree, 차수) : 각 노드의 가지 수
- 트리의 디그리 : 디그리 중 가장 큰 수
- 단말 노드(Terminal Node) = 잎 노드(Leaf Node) : 자식이 없는, 디그리가 0인 노드
- 비단말 노드(Non-Terminal Node) : 자식이 있는 노드, 디그리가 0이 아닌 노드
- 자식 노드(Son Node, Children Node) : 부모가 있는 노드
- 부모 노드(Parent Node) : 자식노드를 가진 노드
- 형제 노드(Brother Node, Sibling) : 동일한 부모를 갖는 노드
- Level : 루트 노드의 Level 1이고, Level이 L인 자식의 Level은 L+1
- 깊이(Depth, Height) : 어떤 Tree에서 노드가 가질 수 있는 최대의 레벨
이진 트리의 운행법
- Preorder(전위) 운행 : Root -> Left -> Right 순서
- Inorder(중위) 운행 : Left -> Root -> Right 순서
- Postorder(후위) 운행 : Left -> Right -> Root 순서
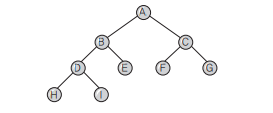
Preorder : ABDHIECFG
Inorder : HDIBEAFCG
Postorder : HIDEBFGCA
수식의 표기법
- 전위 표기법(Prefix) : 연산자 -> Left -> Right
- 중위 표기법(Infix) : Left -> 연산자 -> Right
- 후위 표기법(Postfix) : Left -> Right -> 연산자
정렬(Sort)
내부 정렬
- 소량을 주기억장기에서 정렬
- 종류 : 힙정렬, 삽입 정렬, 셸 정렬, 버블 정렬, 선택 정렬, 퀵 정렬, 2-Way merge 정렬, 기수 정렬(=Radix Sort)
외부 정렬
- 대량을 보조기억장치에서 정렬, 대부분 병합 정렬(Merge Sort)로 처리
- 종류 : 밸런스 병합 정렬, 캐스케이드 병합 정렬, 폴리파즈 병합 정렬, 오실레이팅 병합 정렬
주요 정렬 알고리즘의 이해
삽입 정렬

버블 정렬

선택 정렬

2-Way 합병 정렬(Merge Sort)


이분 검색(이진 검색)
- 순서화된 파일이 전제조건
- 효율 및 소모 시간이 적음
- 검색를 거듭할 수록 데이터 수가 절반으로 줄어듦
- 찾을 값을 중간 값과 비교하며 검색
- 중간 번호 : (첫번째 + 마지막) / 2
해싱(Hashing)
- Hash Table이라는 공간에 해시 함수를 이용하여 레코드 키에 대한 Hash Table내 주소를 계산 후 해당 기억장소에 저장 및 검색을 하는 방식
- DAM(직접 접근 방법)구성시 사용, 접근 속도는 빠르나 공간이 많이 요구
- 검색속도가 가장 빠름
- 삽입, 삭제 작업의 빈도가 많을 시 유리
- 키-주소 변환 방법이라고도 함
해시 테이블(Hash Table)
- 레코드를 1개 이상 보관 가능한 Home Bucket들로 구성된 공간, 보조기억장치 또는 주기억장치에 구성

- 버킷(Bucket) : 주소를 갖는 파일의 한 구역, 버킷의 크기는 한 주소의 레코드 수
- 슬롯(Slot) : 1개 레코드를 저장하는 공간, n개의 슬롯으로 하나의 버킷 형성
- Collision(충돌 현상) : 2 개 이상 레코드가 같은 주소를 가짐
- Synonym : 같은 Home Address를 갖는 레코드들의 집합
- Overflow
- 계산된 Home Address 주소 내 저장공간이 없음
- Bucket을 구성하는 Slot이 여럿일 경우 Collision은 발생해도 Overflow는 발생하지 않을 수 있음
순차 파일(Sequential File) = 순서 파일
- 데이터를 논리적인 순서에 따라 물리적 연속 공간에 순차적으로 기록
- 변동 사항이 적고, 기간별로 일괄 처리를 주로 하는 경우 적합
- 주로 순차 접근이 가능한 자기 테이프에 사용
순차 파일의 장점
- 기억공간을 효율적으로 사용
- 레코드가 키 순서로 편성되어 취급 용이
- 어떤 매체에도 적용 가능
- 처리 속도가 빠름
순차 파일의 단점
- 삽입, 삭제, 수정의 경우 파일 전체를 복사하므로 시간이 많이 소요
색인 순차 파일(Indexed Sequential File)
- 순차 처리와 랜덤 처리가 가능하도록, 레코드를 키 값 순으로 정렬(Sort)시켜 기록
- ISAM (Index Sueuqntial Access Method) 라고도 함
- 참조시 색인 탐색 후 포인터를 사용하여 직접 참조
- 자기 디스크에 사용
색인 순차 파일의 구성
- 기본 구역(Prime Area) : 실제 레코드 기록
- 색인 구역(Index Area) : 색인이 기록되는 부분, 트랙 색인 구역, 실린더 색인 구역, 마스터 색인 구역으로 구분
- 오버플로 구역(Overflow Area) : 기본 구역에 레코드 삽입의 공간이 없음을 대비한 예비 공간
- 실린더 오버플로 구역(Cylinder Overflow Area) : 실린더별 오버플로 구역, 실린더의 기본구역에서 오버플로 된 데이터 기록
- 독립 오버플로 구역(Independent Oveflow Area) : 실린더 오버플로 구역에 데이터 기록불가시, 사용할 공간. 실린더 오버플로 구역과는 별도
색인 순차 파일의 장점
- 순차처리 및 랜덤처리 모두 가능
- 효율적 검색 및 레코드 삽입, 삭제, 갱신 용이
색인 순차 파일의 단점
- 색인 구역 및 오버플로우 구역을 위한 추가 공간 필요
- 파일 정렬 필요, 추가, 삭제가 많으면 효율 저하
- 액세스 시간이 랜덤 편성 파일보다 느림
728x90
반응형
'자격증 > IT' 카테고리의 다른 글
| 정보처리산업기사(필기) - 전자계산기 구조 : 프로세서 2 (명령어, 연산) (0) | 2021.04.04 |
|---|---|
| 정보처리산업기사(필기) - 전자계산기 구조 : 프로세서 1 (중앙처리장치) (0) | 2021.04.01 |
| 정보처리산업기사(필기) - 데이터베이스 : 관계 데이터베이스 모델과 언어 2 (0) | 2021.03.23 |
| 정보처리산업기사(필기) - 데이터베이스 : 관계 데이터베이스 모델과 언어 1 (0) | 2021.03.20 |
| 정보처리산업기사(필기) - 데이터베이스 : 데이터 모델링 및 설계 (0) | 2021.03.15 |

