※ 개인적으로 보고 적는 감상글이기 때문에 정확한 해석이 아니며, 추측성 글임을 참고하시기 바랍니다.

뉴럴 네트워크? 딥러닝 기술을 cloth simulation에 반영하는 내용인 것 같다.

신경망의 depth 안에서 bias값을 조절하는 것 같은 맥락이다.

현재시간을 t라고 하면 속력을 v, location을 x라고 하자.
theta는 시간의 변화에 따른 위치의 변화량을 의미한다. 현재 옷의 상태는 theta_t에 의존하고 location은 x t-1과 x t-2에 의해 결정되는 것 같다.
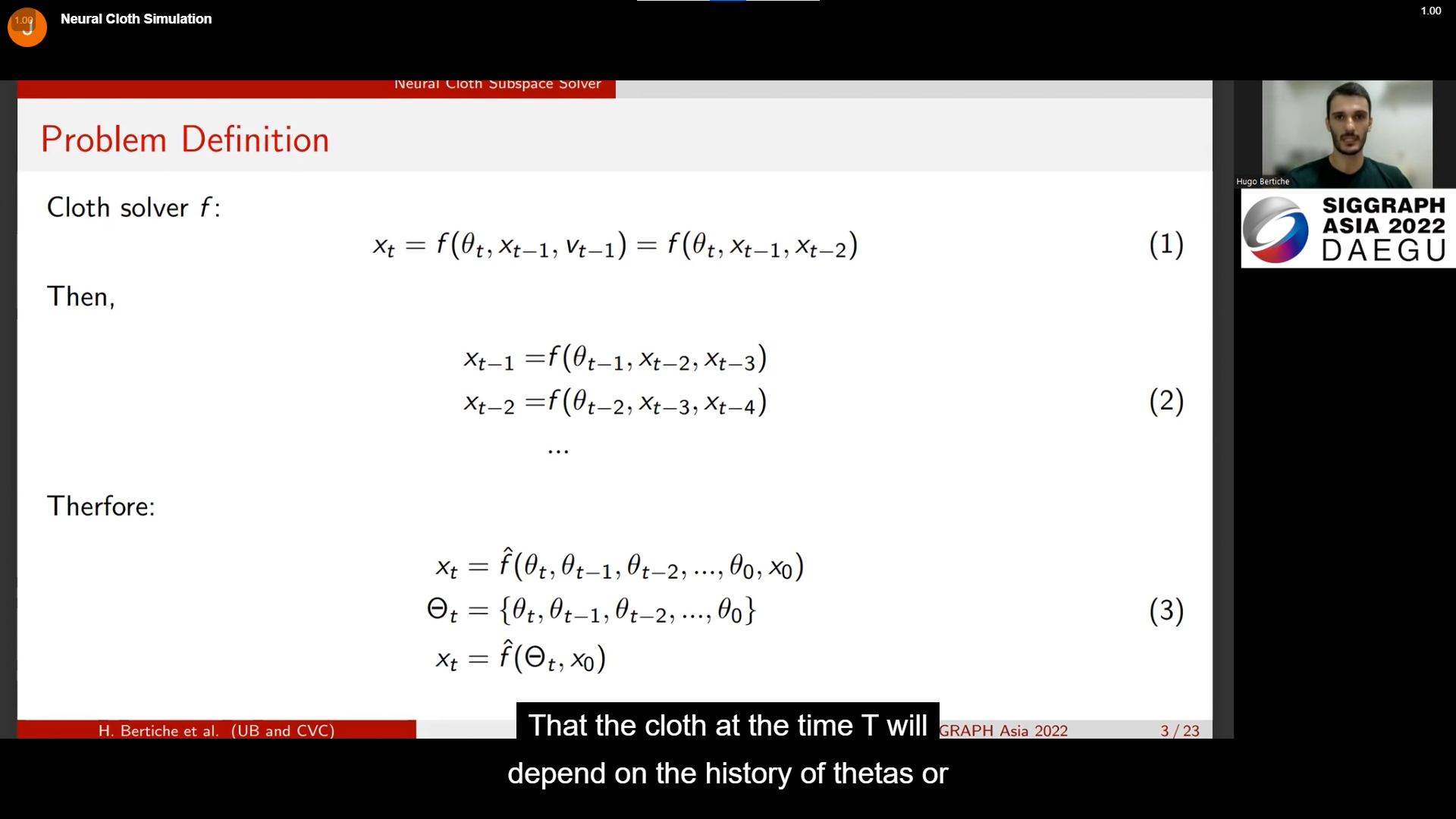
해당 식으로 결론을 도출하는 과정이다. 시간 t는 theta의 history 혹은 body motion에 영향을 받는다고 한다.
결과를 도출하면 이 값은 x에 상당히 비슷해진다는 모양이다.
정확히 이해한지는 모르지만, (3)의 세 줄의 식 중 첫 번째 식이 lower theta의 시간의 흐름에 따른 history와 location을 반영한 것이고, lower theta의 history가 upper theta와 같으므로 결론적으로 마지막 세 번째 줄인 x와 비슷해진다는 맥락으로 보인다.

static case와 dynamic case를 비교한다. static case의 경우 motion이 없는 것으로 간주한다.

cloth 에서 subspace가 있다고 가정하면, upper theta를 subspace z로 가는 건가?

neural network g는 숨어있는 subspace를 찾아 합치는 역할을 하는 것 같다. 이것을 neural cloth subspace solver라고 부른다. 식(6)이 성립하기 위해서는 Z는 변하지 않는다는 모양이다.
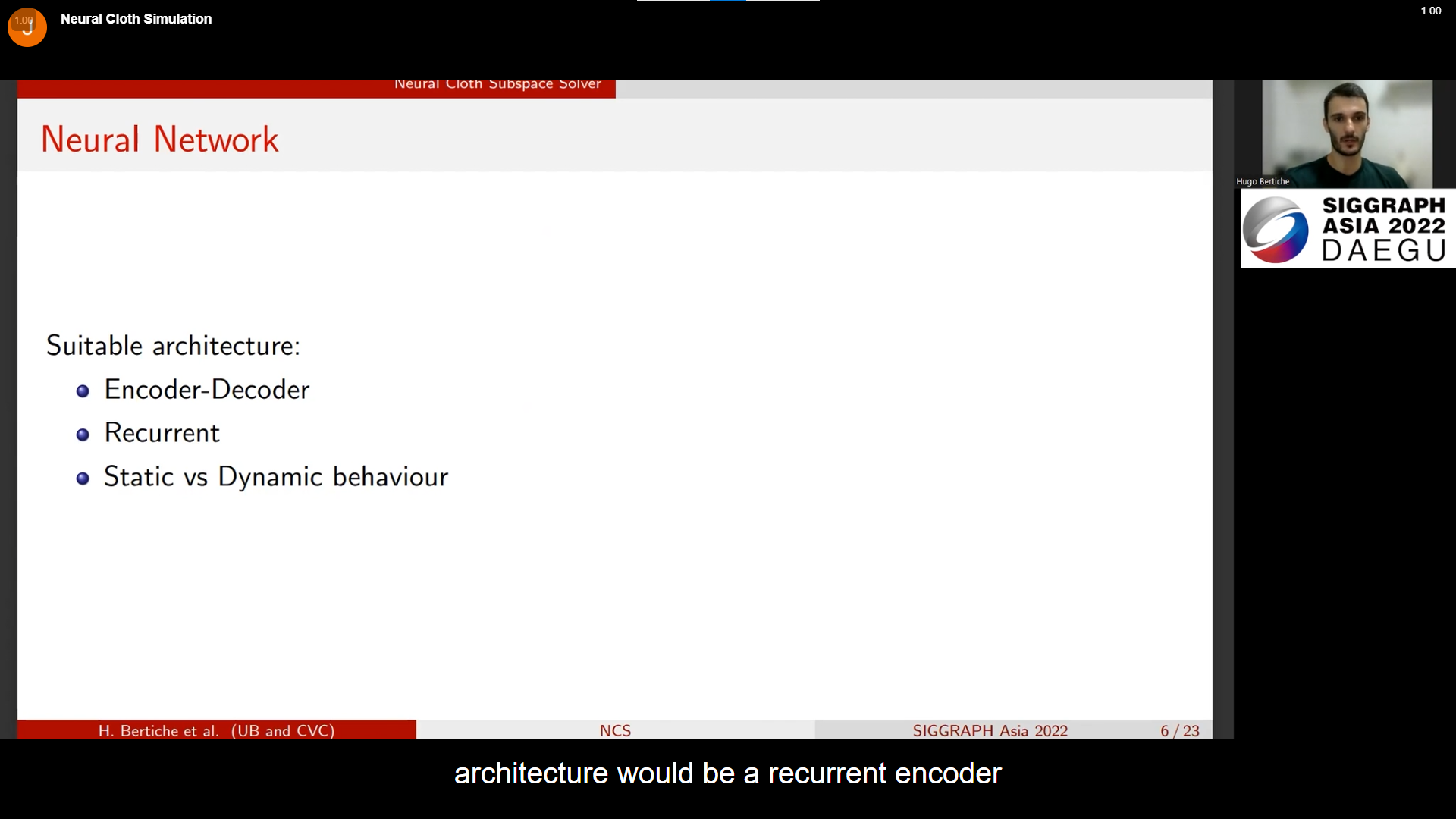
앞서 말한 내용들을 위해 사용하기 적용한 기법들인 모양이다.

해당 논문의 static 모델에 들어갈 input descriptor들이다. axis angle과 quaternion은 빗금 처리가 되어있는데, 이를 사용하는 대신 6차원의 descriptor를 사용했다고 한다. 또한 novel join global orientation을 descriptor로 사용했다고 하는데, 이는 뭔지 잘 모르겠다.

dynamic descriptor는 joint acceleration이라는 것이 있는 모양이다. descriptor에 대해서는 잘 이해하지 못했다.

cloth와 pose가 LVS라는 것으로 융합된다고 한다.

static 인코더에서는 input으로 시간에 따른 운동적인 데이터? 같은것이 들어가는 모양이고, output으로는 시간 t에 대한 static code가 도출된다.

dynamic 인코더에서 input은 반복이 시작되는 순간부터의 dynamic descriptor이고, output은 현재시간 t에 대한 dynamic code이다. dynamic encoder에서는 bias term이 없다고 한다.

bias가 없다면 어떻게 되는가? dynamic descriptor에 비례하는 수치를 보이는데 dynamic descriptor 즉 theta값이 0이 되면, z는 점점 0에 가까워진다. 학습에 있어서 이러한 부분들이 중요한 역할을 하는 것 같다.
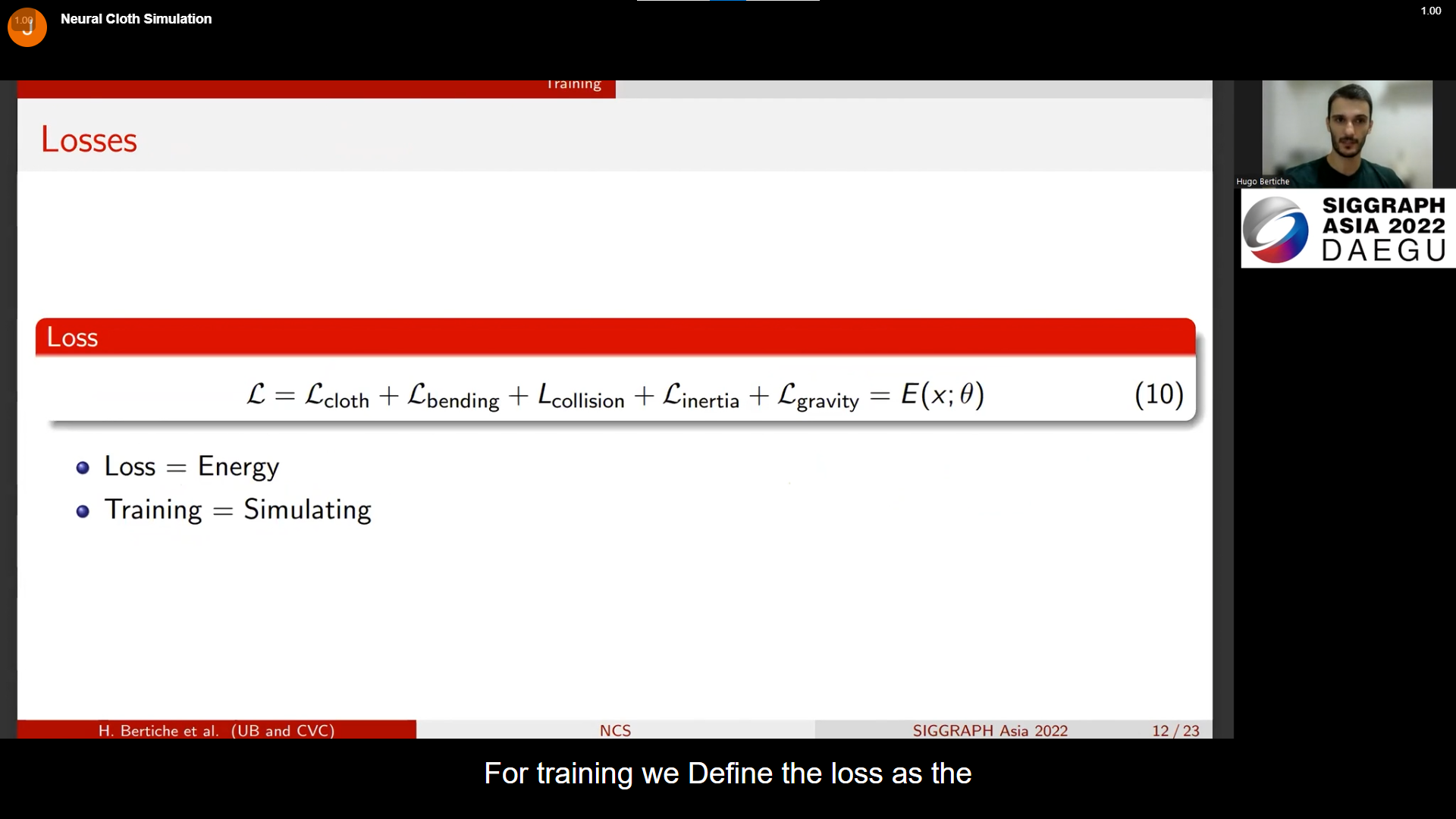
학습에 있어서 손실은 에너지이기 때문에 학습하는 것은 시뮬레이션 하는 것과 같다.
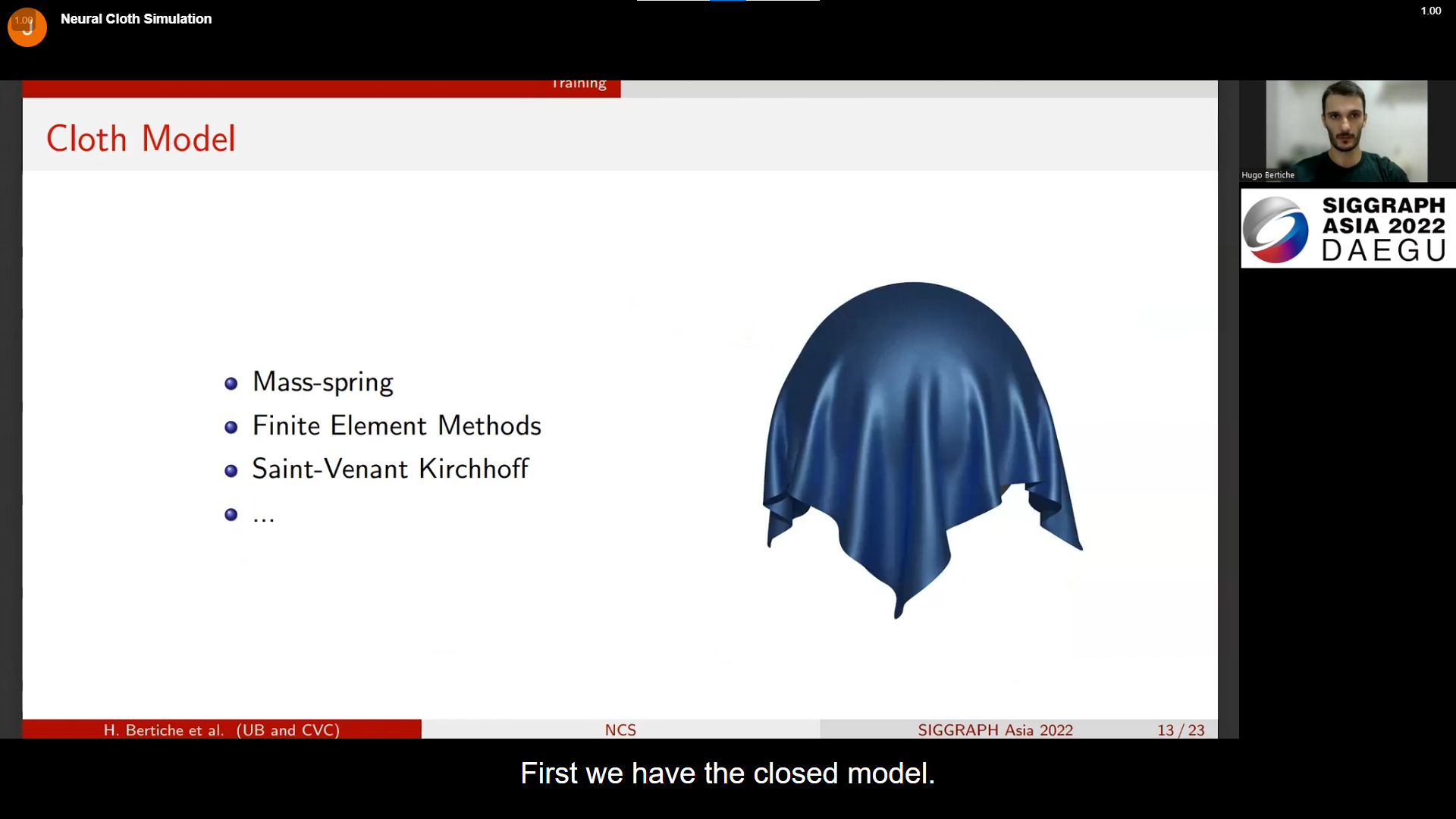
cloth model이 있으면, 각 파트에 대해 다른 공식을 테스트해보며 잘 돌아가는지 확인한다. 그리고 점점 학습으로 성장하는 공식이 요구되면, 미분(?) 한다고 한다.

cloth simulation에 필요한 구부리는 bending을 보면, 이어진 면의 사이가 구부러지는 정도인 dihedral angle과 그 나머지 rest 각도 정보를 통한 식 (11)을 세울 수 있는 것 같다.

충돌로 인한 손실에 대한 식이다. 여기서의 목표는 몸 안쪽 닫혀있는 vertices공간과 옷의 부딪히는 개념을 말하는 것 같다.
학습하는 동안, 몸 밖으로 뭔가 vertices를 밀어내는 듯한 것이 있는 모양인데, 가장 바깥에 있는 버텍스들은 이 충돌 손실에 대해서 0의 값을 가진 모양이다. small threshold라는 임계값이 물체의 견고함을 나타내는 것 같다.
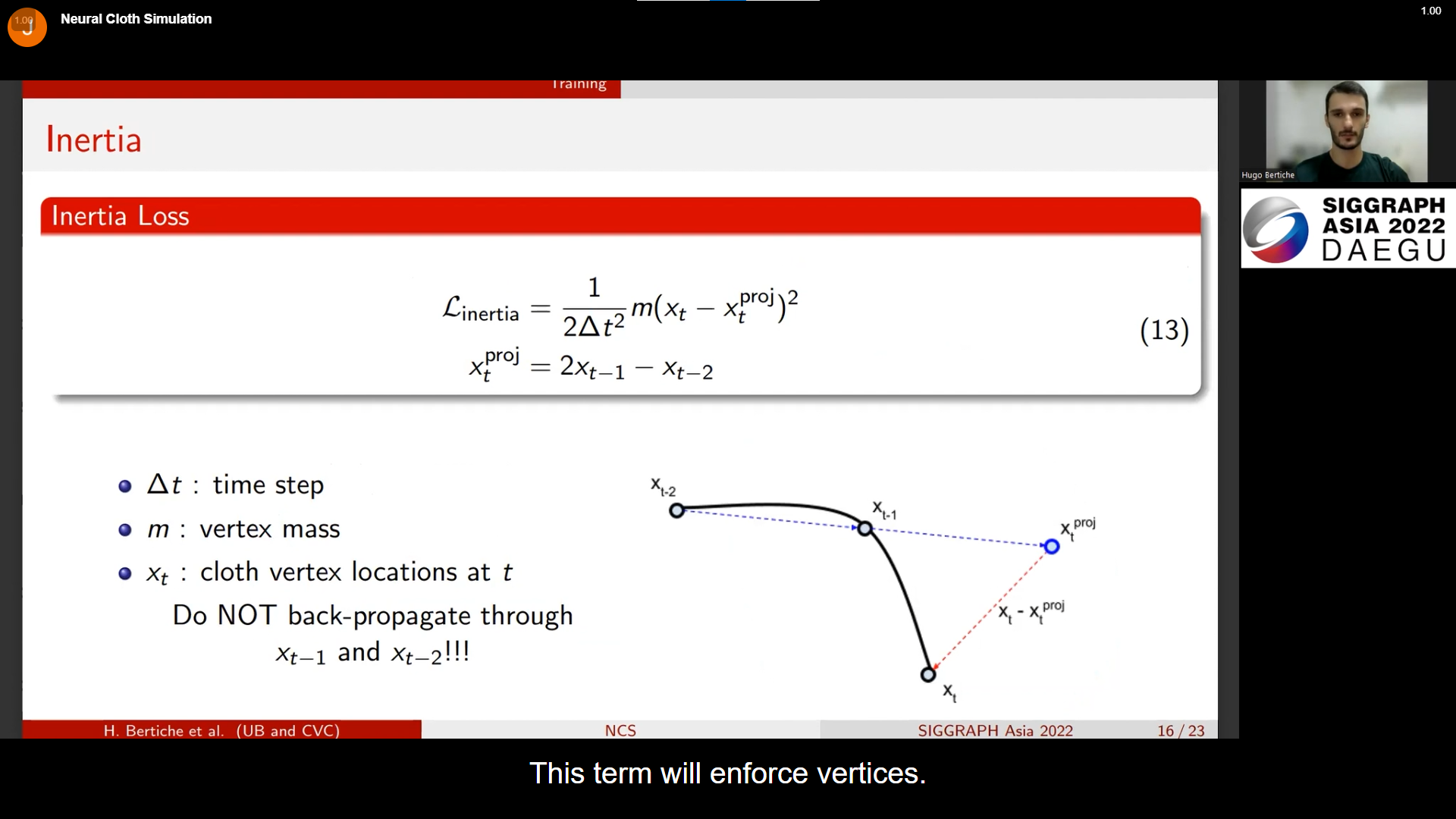
다음은 관성에 관한 것이다. 시간에 따라 관성을 유지해야하는데, 바로 직전인 t-1과 t-2의 x 즉 location을 이용하여 구하는 것 같다.
마지막으로 중력에 대한 내용이다. 중력에도 손실이 있는 것 같은데, 중력의 잠재력을 점점 잃어가는 맥락인 것 같다.

모델을 학습시키기 위해서 시퀀스와 3D 몸 모델이 필요한데, 각각 mixamo와 SMPL에서 모델과 동작을 가져와서 학습을 시켜본 것 같다. SMPL은 학습 중에 모양이 일정하게 유지된다고 한다.

PBNS, SNUG, NCS 이라는 학습 모델들과 Simulation을 비교해본 것 같다. 해당 논문에서의 접근 방식이 가장 실제의 dynamic한 동작에 부합하는 결과를 보여준다.

그림에서 윗줄은 드레스를 입은 마네킹이 회전하는 motion을 담은 것이다. 드레스는 몸을 중심으로 점점 나선 모양으로 twist되는 것을 볼 수 있다.
아래쪽은 각 다른 3d 아바타에 다른 garments 의상 학습시켜본 결과이다.
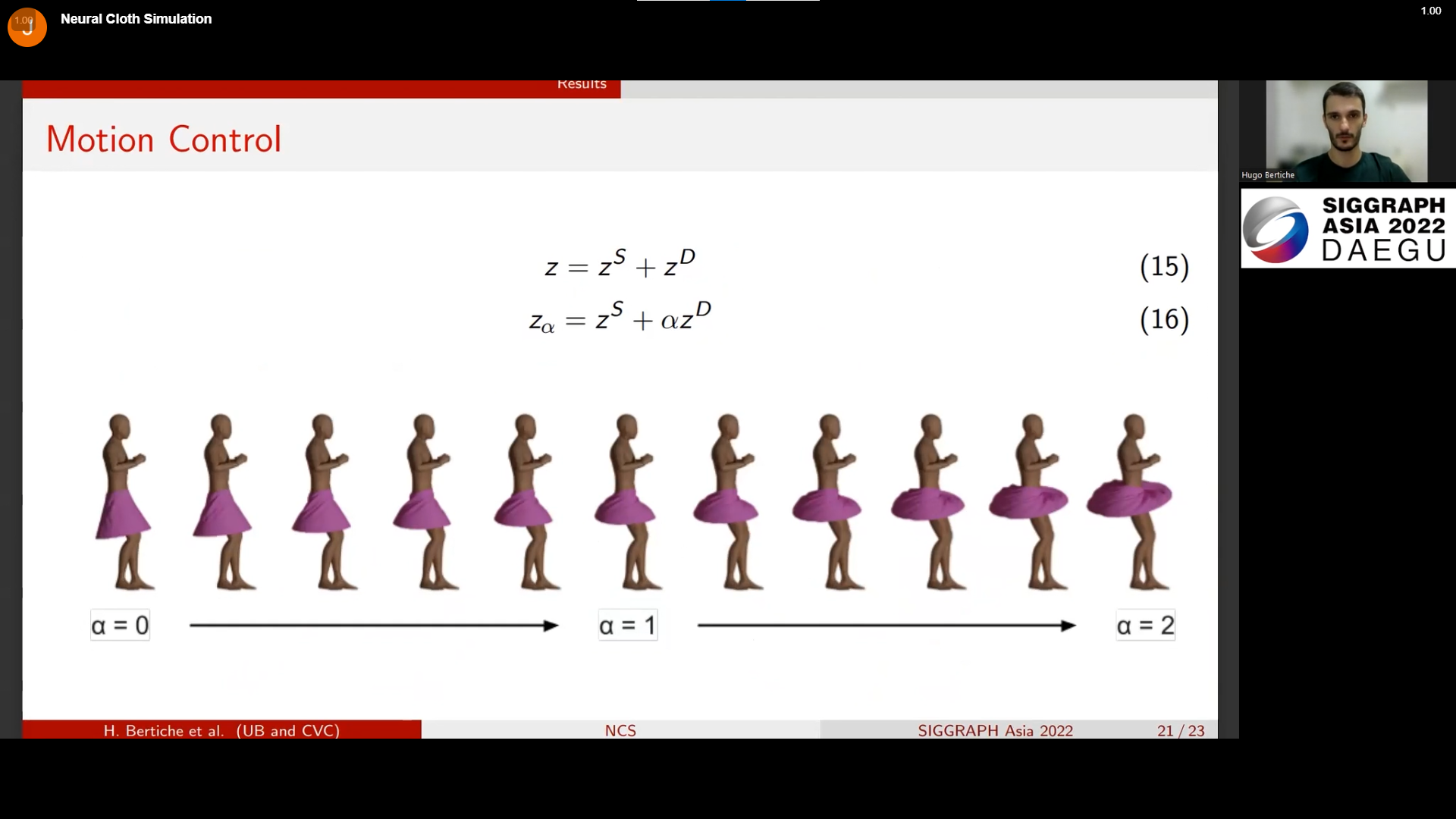
왼쪽에서 오른쪽으로 갈수록 동작이 과장된 형태로 보여진다.

과도한 계산 없이 real-time cloth simulation을 아바타에 맞추어 만들어낼 수 있는 모양이다.

이번 영상을 감상하면서 인공지능 신경망에 대한 수식을 잘 알지못해서 이해하지 못했던 정보들이 많다. 각 변수가 어떤 것을 의미하는지도 잘 와닿지 않고, 그냥 다른 모델과 비교하였을 때 우리의 시뮬레이션은 더 사실적이라는 맥락만 알게 되었던 것 같다. 사실은 그 과정에서 어떤 변화를 주어 바뀌게하였는지가 중요한 것 같은데 말이다.
'개발 · 컴퓨터공학' 카테고리의 다른 글
| [Capstone Project] requestAnimationFrame 이 무엇인가 (0) | 2023.02.03 |
|---|---|
| [Capstone Project] vertexMappingArray를 통해 vertex 적용하기 (0) | 2023.02.02 |
| [Capstone Project] blender mirror / vertex symmetry에 대해서 (0) | 2023.01.30 |
| [Capstone Project] vertex 중복제거 array 꺼내오기 (0) | 2023.01.27 |
| [Capstone Project] Raycaster를 이용한 Cylinder docs 예제에서의 vertex구조 (2) | 2023.01.26 |



